Генофонд.рф / Языки, гены, народы / Перестановочный тест частично подтверждает существование алтайской языковой макросемьи
Перестановочный тест частично подтверждает существование алтайской языковой макросемьи
17.06.2021
Скачать страницу в PDF
 Современное распределение пяти языковых семей, входящих в алтайскую макросемью (Kassian et al., 2021)
Публикуем обзор статьи (Kassian et al., 2021) Permutation test applied to lexical reconstructions partially supports the Altaic linguistic macrofamily от одного из ее соавторов. В статье методами компаративистики показана неслучайность сходств языковых семей, входящих в алтайскую макросемью.
Илья Егоров, н.с. ШАГИ РАНХиГС (Москва)
Алтайская проблема
Алтайская гипотеза предполагает родство, т.е. происхождение от общего языка-предка, пяти языковых семей Евразии: тюркской, монгольской, тунгусо-маньчжурской, японской (кроме японских диалектов включает рюкюские языки) и корейского языка. Эта гипотеза существует в двух версиях. “Узкая” версия предполагает только родство тюркских, монгольских и тунгусо-маньчжурских языков. В московской школе компаративистики их принято называть ядерными алтайскими языками. “Широкая” версия включает также корейский и японский. Все вместе это называется алтайской макросемьей. Иногда термин алтайская (макро)семья используют только для клады, включающей тюркские, монгольские и тунгусо-маньчжурские языки, а говоря о единстве с корейский и японским, употребляют термин трансевразийская макросемья.
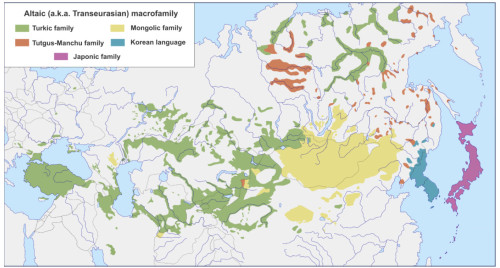 Рисунок 1. Современная территория распространения языковых семей, которые включаются в алтайскую (трансевразийскую) макросемью.
Алтайская гипотеза в ее узком варианте с добавлением корейского была сформулирована Густавом Рамстедтом еще в начале ХХ века (см. Рамстедт 1957). Однако первая последовательная фонетическая реконструкция праалтайского языка появилась только на рубеже тысячелетий с выходом “Этимологического словаря алтайских языков” (Starostin, Dybo, Mudrak 2003). Гипотеза Рамстедта вызвала активную критику со стороны специалистов по отдельным семьям, с выходом алтайского словаря поднялась новая волна критики. История споров об алтайской проблеме изложена в обобщающей книге Вацлава Блажека (2019), которая также является хорошим введением в алтаистику.
Неслучайность сходств в фонетике, грамматике и лексике тюркских, монгольских и тунгусо-маньчжурских языков можно считать общепризнанной. Но трактовка этих сходств различна. Противники алтайской гипотезы утверждают, что они вызваны тесными и очень продолжительными контактами. Сторонники теории алтайского родства связывают часть сходств с общим происхождением этих языков, обычно признавая, что другие сходства вызваны языковыми контактами. Контактное объяснение возможно и для корейского с японским. Неслучайность сходств между двумя гипотетическими кладами ядерной алтайской и японско-корейской нуждается в дополнительном обосновании.
Доказательство родства vs предворительное сравнение
Стандартным доказательством языкового родства считается нахождение регулярных фонетических соответствий в базисной лексике. Базисная лексика — часть словаря, не зависящая от типа культуры и демонстрирующая особенную устойчивость.
На практике поиску регулярных фонетических соответствий обычно предшествует этап, когда лингвист “на глазок” оценивает сходство лексики. Формализовать этот этап работы можно путем сравнения слов по консонантным классам. Консонантные фонемы, т.е., проще говоря, согласные, подвержены изменению с ходом времени гораздо меньше, чем гласные. При этом изменения в глухости / звонкости, мягкости / твердости, придыхательности или в таких деталях, как приподнятость или опущенность кончика языка (сравните английский t и русский т), встречаются все-таки довольно часто. Если как бы закрыть глаза на эти менее существенные признаки, то согласные можно объединить в определенные классы, например П-образные, Т-образные, Н-образные, М-образные, Р-образные, шипяще-свистящие и т.д.
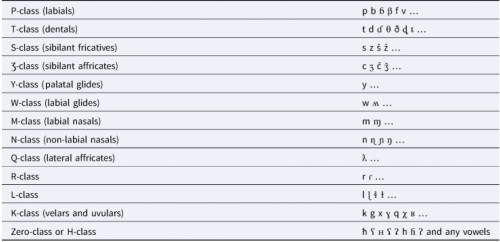 Таблица 1. Консонантные классы.
Каждое привлекаемое к сравнению слово редуцируется до консонантных классов. Поскольку одна из самых частотных моделей корня в языках Евразии — это согласный-гласный-согласный, удобно сравнивать структуры из двух согласных. Например, прамонгольское слово *nogoha ‘зеленый’ превращается в NK, также как и пратунгксское *ɲog ‘зеленый’, а прамонгольское *čila ‘камень’ и пратунгусское *ǯolo ‘камень’ становятся ƷL.
А что, собственно, сравниваем?
Как уже было сказано, для доказательства родства нужно исследовать в первую очередь базисную лексику. Один из самых популярных списков базисной лексики — 100-словный список Морриса Сводеша. Московской школой компаративистики в 2010 году была разработана версия этого списка со строгим уточнением каждого значения (Kassian et al. 2010). Было, например, установлено, что в значении ‘нога’ нужно брать эквивалент ‘foot’, а не ‘leg’; в значении ‘плавать’ брать глагол описывающий действия человека, а не лодки или бревна.
Для исследований в области дальнего языкового родства ключевым является принцип ступенчатости реконструкции. Это значит, что к сравнению привлекаются не слова современных языков, а реконструированные формы праязыков, чье существование не вызывает сомнений. Так, говоря об алтайском родстве, мы должны работать с пратюркскими, прамонгольскими, пратунгусскими, пракорейскими и праяпонскими формами. На практике успешную реконструкцию удается сделать только для четырех семей. Данные древнекорейских памятников и корейских диалектов слишком скудные, чтобы можно было сделать надежную реконструкцию списка Сводеша. Поэтому вместо пракорейского используется список, собранные по памятникам позднего среднекорейского периода (XV-XVI вв.).
Фонетическая реконструкция — довольно строгая процедура, но все же она допускает некоторую свободу в интерпретации. Разные исследователи могут восстанавливать немного разные фонемы праязыка на основании одних и тех же регулярных соответствий или признавать разные системы соответствия. Иногда эти расхождения могут быть серьезными и касаться принадлежности согласного к одному или другому консонантному классу. Так в случае с японским Сергей Анатольевич Старостин реконструировал d- в тех местах, где другие лингвисты реконструируют y-. Это обстоятельство заставляет использовать две версии праяпонской реконструкции.
Если фонетическая реконструкция уже давно является строгим методом, то реконструкция значения долгое время делалось на глазок. Ноу-хау московской школы компартивистики — строгий метод ономасиологической реконструкции. Ономасиологическая реконструкция предполагает, что исследователь подбирает оптимальный корень (или основу), которым могло выражаться данное значение в праязыке. Иными словами, это реконструкция от значения к форме. Строгим этот метод делают 5 критериев, по которым осуществляется такой отбор:
- Представленность корня в разных подгруппах языковой семьи должна быть такая, чтоб она предполагала минимальное количество семантических переходов в истории языков этой семьи.
- Даже если корень нашелся в языках разных подгрупп, они не должны быть географически смежными. Это нужно чтобы исключить заимствования и ареальные влияния.
- Если корень имеет внешние параллели за пределами семьи или группы, он более предпочтителен, чем тот, что представлен лишь в данной группе или семье.
- Предпочтение отдается непроизводным корням, а основы с аффиксами и корнесложения считаются более слабыми кандидатами.
- Сценарий изменений значения корня в отдельных языках должен предполагать типологически более вероятные развития с точки зрения типологии семантических переходов.
Таким образом было реконструировано четыре списка (пратюркский, прамонгольский, пратунгусо-маньчжурский, праяпонский), при этом японский в двух версиях (с d-реконструкцией С.А. Старостина и с консервативной y-реконструкцией), и один список собран по среднекорейским памятникам.
Как доказать, что сходства неслучайны?
Для доказательства неслучайности сходств используется перестановочный тест. Принцип перестановочного теста прост. Одинаковые структуры из двух согласных (биконсонантные структуры) в каждой паре языков помечаются как совпадения. Дальше один из списков перемешивается в случайном порядке, и снова оценивается количество совпадений. Если сделать таких перестановок достаточно много, то можно понять среднюю вероятность случайного совпадения биконсонантных структур между списками. На основе этого показателя можно оценить, какова вероятность того, что совпадения, имеющиеся в исходных списках случайные. Чем меньше такая вероятность, тем более статистически значимы эти совпадения. Так выглядит классический перестановочный тест, он не взвешенный, это значит, что все потенциальные совпадения биконсонантных структур имеют одну цену (один вес).
Но в настоящей работе использован взвешенный перестановочный тест (еще одно ноу-хау московской школы), который устроен следующим образом. 110 сводешевских концептов ранжированы по своей типологической устойчивости, например, слово ‘глаз’ в целом стабильнее в языках мира, чем слово ‘грудь’, слово ‘новый’ стабильнее, чем слово ‘круглый’. Чем выше индекс стабильности у концепта, тем выше цена за биконсонантное совпадение в этом концепте. Дешевизна совпадений в низко стабильных концептах оправдана тем, что чем менее стабилен концепт, тем выше вероятность лексической замены, которая, в свою очередь, может быть случайно созвучна слову из другого языка.
Что показало автоматическое сравнение?
Алгоритм обнаружил 66 пар биконсонантных совпадений в списках Сводеша пяти языковых семей. Сравним этот результат со взглядом авторов “Этимологического словаря алтайских языков”, в котором этимологически родственные слова определяются по регулярным фонетическим соответствиям, а не по консонантным классам. Получается, что среди выявленных алгоритмом соответствий 11 (17%) ложноположительные, т.е. эксперты их не признают родственными. А еще 74 пары, которые лингвисты считают родственными, алгоритм не выявил. В этих случаях фонетические изменения привели к смене консонантного класса. Относительно небольшое количество ложноположительных результатов можно считать достоинством метода.
Перестановочный тест показал высокую статистическую значимость совпадений между ядерными алтайскими семьями (тюркской, монгольской и тунгусо-маньчжурской). Сравнение с японским дало более слабый результат: статистическую значимость имеют только японско-тюркские и японско-тунгусские совпадения.
А вот совпадения лексики любого из четырех языков с корейским статистической значимости не показали. Это может быть связано с историей корейской фонетики. Большинство неначальных согласных в этом языке исчезли, а в начале некоторых слов добавилось s. Эти процессы очень сильно изменили структуру корня. Неудивительно, что в такой ситуации метод консонанных классов не смог найти достаточно совпадений в других алтайских семьях.
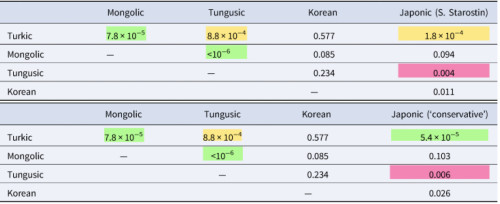 Таблица 2. Вероятность фонетических совпадений между пятью семьями, составляющими гипотетическую алтайскую макро-семью, по данным взвешенного перестановочного теста. Сверху результаты с использованием праяпонской реконструкции С.А. Старостина, снизу с консервативной реконструкцией. Цветом обозначены статистически значимые значения: зеленым — α = 0.001; желтым — α = 0.01; красным — α = 0.05.
Доказано ли родство?
Может ли перестановочный тест доказать родство языков? Строго говоря, нет. Для доказательства родства недостаточно просто показать, что какие-то слова похожи. Должна быть продемонстрирована регулярность фонетических соответствий. Можно даже сказать, что систематические различия интересуют компаративистов намного больше, чем внешнее сходство слов. Статистически значимые результаты перестановочного теста, скорее, нужно трактовать как эвристическое указание на связь языков. Но эта связь может быть как генетической, так и обусловленной контактами.
Вместе с тем, отсутствие статистически значимых результатов перестановочного теста для биконсонантных структур не опровергает родство языков. Хотя мы и ожидаем, что большинство фонетических изменений происходит в пределах одного консонантного класса, ничто не запрещает фонетические процессы, приводящие к смене класса. Например, переход č > s или z > r довольно часто встречается в языках мира, не говоря уже просто об отпадении конечных согласных.
Высокая статистическая значимость совпадений между ядерными алтайскими семьями (тюркской, монгольской и тунгусо-маньчжурской) позволяет трактовать их и как результат контактов, и как следы генетического родства. Мы знаем, что контакты между языками этих семей имели место в древности и продолжаются по сей день. Другое дело статистически значимые совпадения в парах японский-тунгусский и японский-тюркский. Ввиду географической близости можно было бы спекулировать о древних японско-тунгусских контактах (хотя, конечно, намного больше это похоже на древнее родство). Но вот контактный сценарий с заимствованной лексикой между пратюркским и праяпонским требовал бы некоторых сильных допущений по причине громадной географической дистанции между ареалами этих языковых семей. Сценарий языкового родства в тюркско-японском случае представляется куда более экономным.
Оригинальная статья
Kassian, A., Starostin, G., Egorov, I., Logunova, E., & Dybo, A. (2021). Permutation test applied to lexical reconstructions partially supports the Altaic linguistic macrofamily. Evolutionary Human Sciences, 3, E32. doi:10.1017/ehs.2021.28
Литература
Рамстедт, Г.И. (1957). Введение в алтайское языкознание. Москва.
Blažek, V. (2019). Altaic languages: History of research, survey, classification and a sketch of comparative grammar. Masaryk University Press.
Kassian, A. S., Starostin, G., Dybo, A., & Chernov, V. (2010). The Swadesh wordlist. An attempt at semantic specification. Journal of Language Relationship, 4, 46–89.
Starostin, S. A., Dybo, A. V., & Mudrak, O. A. (2003). Etymological dictionary of the Altaic languages (Vols 1–3). Brill.
|
Избранное
Анализ древних геномов с запада Иберийского полуострова показал увеличение генетического вклада охотников-собирателей в позднем неолите и бронзовом веке. След степной миграции здесь также имеется, хотя в меньшей степени, чем в Северной и Центральной Европе.
|
Геологи показали, что древний канал, претендующий на приток мифической реки Сарасвати, пересох еще до возникновения Индской (Хараппской) цивилизации. Это ставит под сомнение ее зависимость от крупных гималайских рек.
|
Текст по пресс-релизу Института археологии РАН о находке наскального рисунка двугорбого верблюда в Каповой пещере опубликован на сайте "Полит.ру".
|
На основе изученных геномов бактерии Yersinia pestis из образцов позднего неолита – раннего железного века палеогенетики реконструировали пути распространения чумы. Ключевое значение в ее переносе в Европу они придают массовой миграции из причерноморско-каспийских степей около 5000 лет назад. По их гипотезе возбудитель чумы продвигался по тому же степному коридору с двусторонним движением между Европой и Азией, что и мигрирующее население.
|
Генетическое разнообразие населения Сванетии в этой работе изучили по образцам мтДНК и Y-хромосомы 184 человек. Данные показали разнообразие митохондриального и сравнительную гомогенность Y-хромосомного генофонда сванов. Авторы делают вывод о влиянии на Y-хромосомный генофонд Южного Кавказа географии, но не языков. И о том, что современное население, в частности, сваны, являются потомками ранних обитателей этого региона, времен верхнего палеолита.
|
Опубликовано на сайте Коммерсант.ru
|
Авторы свежей статьи в Nature опровергают представления о почти полном замещении охотников-собирателей земледельцами в ходе неолитизации Европы. Он и обнаружили, что генетический вклад охотников-собирателей различается у европейских неолитических земледельцев разных регионов и увеличивается со временем. Это говорит, скорее, о мирном сосуществовании тех и других и о постоянном генетическом смешении.
|
Последние дни у нас веселые – телефон звонит, не переставая, приглашая всюду сказать слово генетика. Обычно я отказываюсь. А здесь все одно к одному - как раз накануне сдали отчет на шестистах страницах, а новый – еще только через месяц. И вопросы не обычные - не про то, когда исчезнет последняя блондинка или не возьмусь ли я изучить геном Гитлера. Вопросы про президента и про биологические образцы.
|
В Медико-генетическом научном центре (ФГБНУ МГНЦ) 10 ноября прошла пресс-конференция, на которой руководители нескольких направлений рассказали о своей работе, связанной с генетическими и прочими исследованиями биологических материалов.
|
Горячая тема образцов биоматериалов обсуждается в программе "В центре внимания" на Радио Маяк. В студии специалисты по геногеографии и медицинской генетике: зав. лаб. геномной географии Института общей генетики РАН, проф. РАН Олег Балановский и зав. лаб. молекулярной генетики наследственных заболеваний Института молекулярной генетики РАН, д.б.н., проф. Петр Сломинский.
|
О совсем недавно открытой лейлатепинской культуре в Закавказье, ее отличительных признаков и корнях и ее отношениях с известной майкопской культурой.
|
Интервью О.П.Балановского газете "Троицкий вариант"
|
В издательстве «Захаров» вышла книга «Эта короткая жизнь: Николай Вавилов и его время». Ее автор Семен Ефимович Резник, он же автор самой первой биографической книги о Н.И.Вавилове, вышедшей в 1968 году в серии ЖЗЛ.
|
Исследование генофонда четырех современных русских популяций в ареале бывшей земли Новгородской позволяет лучше понять его положение в генетическом пространстве окружающих популяций. Он оказался в буферной зоне между северным и южным «полюсами» русского генофонда. Значительную (пятую) часть генофонда население Новгородчины унаследовало от финноязычного населения, которое, видимо, в свою очередь, впитало мезолитический генофонд Северо-Восточной Европы. Генетические различия между отдельными популяциями Новгородчины могут отражать особенности расселения древних славян вдоль речной системы, сохранившиеся в современном генофонде вопреки бурным демографическим событиям более поздних времен.
|
На "Эхе Москвы" в программе "Культурный шок" беседа глав. ред. Алексея Венедиктова с д.б.н., зав. кафедрой биологической эволюции Биологического факультета МГУ Александром Марковым.
|
О том, неужели кто-то пытается придумать биологическое оружие против граждан России — материал Марии Борзуновой (телеканал "Дождь").
|
Отличная статья на сайте "Московского комсомольца"
|
Что такое биоматериал? Где он хранится и как используется? Об этом в эфире “Вестей FM” расскажут директор Института стволовых клеток человека Артур Исаев и заведующий лабораторией геномной географии Института общей генетики имени Вавилова, доктор биологических наук, профессор РАН Олег Балановский.
|
Что стоит за высказыванием В.В.Путина о сборе биологических материалов россиян, и реакцию на его слова в студии "Радио Свобода" обсуждают: политик Владимир Семаго, доктор биологических наук, генетик Светлана Боринская, руководитель лаборатории геномной географии Института общей генетики РАН Олег Балановский.
|
Как сказал ведущий программы «Блог-аут» Майкл Наки, одна из самых обсуждаемых новостей недели – это высказывание Владимира Путина, про то, что собираются биоматериалы россиян – массово и по разным этносам. И это было бы смешно, когда бы не было так грустно - если бы после этого высказывания всякие каналы не начали выпускать сюжеты о биооружии, которое готовится против россиян. По поводу этой странной истории ведущий беседует с д.б.н., проф. РАН О.П.Балановским.
|
Ведущие специалисты в области генетики человека считают напрасными страхи перед неким «этническим оружием». Сделать его невозможно.
|
Комментируем ситуацию вокруг вопроса Президента РФ, кто и зачем собирает биологический материал россиян.
|
В африканских популяциях, как выяснилось, представлено большое разнообразие генетических вариантов, отвечающих за цвет кожи: не только аллели темной кожи, но и аллели светлой кожи. Последних оказалось особенно много у южноафриканских бушменов. Генетики пришли к заключению, что варианты, обеспечивающие светлую кожу, более древние, и возникли они в Африке задолго до формирования современного человека как вида.
|
Анализ генома 40-тысячелетнего человека из китайской пещеры Тяньянь показал его генетическую близость к предкам восточноазиатских и юговосточных азиатских популяций и указал на картину популяционного разнообразия в верхнем палеолите. Исследователи полагают, что 40-35 тыс. лет назад на территории Евразии обитали не менее четырех популяций, которые в разной степени оставили генетический след в современном населении.
|
В Санкт-Петербургском государственном университете, в Петровском зале здания Двенадцати коллегий состоялись чтения, посвященные 90-летию со дня рождения Льва Самуиловича Клейна. Большинство из выступавших на них археологов, антропологов, историков и других специалистов считают себя его учениками, которым он привил основы научного мышления, научил идти непроторенными дорогами, показал пример преодоления обстоятельств и стойкости в борьбе. Научные доклады начинались со слов признательности учителю. Представляем здесь выступление доктора исторических наук, профессора СПбГУ, главного научного сотрудника Музея антропологии и этнографии РАН Александра Григорьевича Козинцева.
|
Накануне 110-летия со дня рождения знаменитого антрополога и скульптора, автора всемирно известного метода реконструкции лица по черепу Михаила Михайловича Герасимова, в Дарвиновском музее прошел вечер его памяти. О том, как появился знаменитый метод, о работах мастера и развитии этого направления в наши дни рассказали его последователи и коллеги.
|
Генетики секвенировали митохондриальную ДНК 340 человек из 17 популяций Европы и Ближнего Востока и сравнили эти данные с данными по секвенированию Y-хромосомы. Демографическая история популяций, реконструированная по отцовским и материнским линиям наследования, оказалась совершенно разной. Если первые указывают на экспансию в период бронзового века, то вторые хранят память о расселении в палеолите после окончания оледенения.
|
Анализ геномов четырех индивидов с верхнепалеолитической стоянки Сунгирь показал, что они не являются близкими родственниками. Из этого авторы работы делают вывод, что охотники-собиратели верхнего палеолита успешно избегали инбридинга, так как каждая группа была включена в разветвленную сеть по обмену брачными партнерами.
|
Изучив 16 древних геномов из Африки возрастом от 8100 до 400 лет, палеогенетики предлагают картину смешений и перемещений, приведшую к формированию современных африканских популяций.
|
Анализ семи древних геномов из Южной Африки показал глубокие генетические различия между бушменами и прочими африканскими и неафриканскими популяциями. Время формирования первой развилки на древе человечества соответствует периоду формирования современного человека как вида, авторы оценили его в диапазоне от 350 до 260 тысяч лет назад.
|
Генетический ландшафт Папуа Новая Гвинея отмечен кардинальными различиями между горными и равнинными популяциями. Первые, в отличие от вторых, не обнаруживают влияния Юго-Восточной Азии. Среди горных популяций отмечается высокое генетическое разнообразие, возникшее в период возникновения земледелия. Делается вывод, что неолитический переход не всегда приводит к генетической однородности населения (как в Западной Евразии).
|
В неолитизации Европы роль культурной диффузии была очень незначительной. Основную роль играло распространение земледельцев с Ближнего Востока, которые почти полностью замещали местные племена охотников-собирателей. Доля генетического смешения оценивается в 2%. К таким выводам исследователей привел анализ частоты гаплогрупп митохондриальной ДНК и математическое моделирование.
|
Сочетание генетического и изотопного анализа останков из захоронений на юге Германии продемонстрировало патрилокальность общества в позднем неолите – раннем бронзовом веке. Мужчины в этом регионе вели оседлый образ жизни, а женщины перемещались из других регионов.
|
Наш постоянный читатель и активный участник дискуссий на сайте Лев Агни поделился своим мнением о том, что противопоставить изобилию некачественных научных публикаций в области истории.
|
Древние геномы изучили по аллелям, ассоциированным с болезнями, и вычислили генетический риск наших предков для разных групп заболеваний. Оказалось, что этот риск выше у более древних индивидов (9500 лет и старше), чем у более молодых (3500 лет и моложе). Обнаружилась также зависимость генетического риска заболеваний от типа хозяйства и питания древних людей: скотоводы оказались более генетически здоровыми, чем охотники-собиратели и земледельцы. Географическое местоположение лишь незначительно повлияло на риск некоторых болезней.
|
Международная группа археологов опровергла датировку выплавки меди в Чатал-Хююке – одном из самых известных поселений позднего неолита в центральной Турции. Статья с результатами исследования опубликована в журнале Journal of Archaeological Science .
|
В продолжение темы майкопской культуры перепечатываем еще одну статью археолога, канд. ист. наук Н.А.Николаевой, опубликованную в журнале Вестник Московского государственного областного университета (№1, 2009, с.162-173)
|
В продолжение темы, рассмотренной в статье А.А.Касьяна с лингвистических позиций, и с разрешения автора перепечатываем статью археолога, к.и.н. Надежды Алексеевны Николаевой, доцента Московского государственного областного университета. Статья была опубликована в 2013 г. в журнале Восток (Оriens) № 2, С.107-113
|
Частичный перевод из работы Алексея Касьяна «Хаттский как сино-кавказский язык» (Alexei Kassian. 2009–2010. Hattic as a Sino-Caucasian language. Ugarit-Forschungen 41: 309–447)
|
Несмотря на признание исследований по географии генофондов со стороны мирового научного сообщества и все возрастающую роль геногеографии в междисциплинарных исследованиях народонаселения, до сих пор нет консенсуса о соотношении предметных областей геногеографии и этнологии. Генетики и этнологи часто работали параллельно, а с конца 2000-х годов началось их тесное сотрудничество на всех этапах исследования – от совместных экспедиций до совместного анализа и синтеза. Приведены примеры таких совместных исследований. Эти примеры демонстрируют, что корректно осуществляемый союз генетики и этнологии имеет добротные научные перспективы.
|
Генетический анализ показал, что население Мадагаскара сформировалось при смешении предков африканского происхождения (банту) и восточноазиатского (индонезийцы с Борнео). Доля генетических компонентов разного происхождения зависит от географического региона: африканского больше на севере, восточноазиатского – на юго-востоке. На основании картины генетического ландшафта авторы реконструируют историю заселения Мадагаскара – переселенцы из Индонезии появились здесь раньше, чем африканцы.
|
Появились доказательства того, что анатомически современный человек обитал на островах Индонезии уже в период от 73 до 63 тыс. лет назад, статья с результатами этой работы опубликована в Nature.
|
Анализ геномов бронзового века с территории Ливана показал, что древние ханаанеи смешали в своих генах компоненты неолитических популяций Леванта и халколитических - Ирана. Современные ливанцы получили генетическое наследие от ханаанеев, к которому добавился вклад степных популяций.
|
В журнале European Journal of Archaeology опубликована дискуссия между проф. Л.С.Клейном и авторами статей в Nature (Haak et al. 2015; Allentoft 2015) о гипотезе массовой миграции ямной культуры по данным генетики и ее связи с происхождением индоевропейских языков. Дискуссия составлена из переписки Л.С.Клейна с несколькими соавторами (Вольфганг Хаак, Иосиф Лазаридис, Ник Пэттерсон, Дэвид Райх, Кристиан Кристиансен, Карл-Гёран Шорген, Мортен Аллентофт, Мартин Сикора и Эске Виллерслев). Публикуем ее перевод на русский язык с предисловием Л.С.Клейна.
|
Анализ ДНК представителей минойской и микенской цивилизаций доказал их генетическое родство между собой, а также с современными греками. Показано, что основной вклад в формирование минойцев и микенцев внесли неолитические популяции Анатолии. Авторы обнаружили у них генетический компонент, происходящий с Кавказа и из Ирана, а у микенцев – небольшой след из Восточной Европы и Сибири.
|
Африка – прародина современного человека. Тем не менее генетические данные о древнем населении Африки до сего времени были совершенно незначительными – всего один прочитанный древний геном из Эфиопии возрастом 4,5 тысячи лет. Причины понятны – в экваториальном и тропическом климате ДНК плохо сохраняется и непригодна для изучения. Но вот сделан большой шаг вперед в этом направлении – секвенированы сразу семь древних африканских геномов, о чем поведала статья генетиков из Университета Упсалы, Швеция, опубликованная на сайте препринтов.
|
Публикуем заключительную часть статьи археологов из Одесского университета проф. С.В. Ивановой и к.и.н. Д.В. Киосака и археогенетика, проф. Grand Valley State University А.Г. Никитина. Предмет исследования — археологическая и культурная картина Северо-Западного Причерноморья эпохи энеолита — ранней бронзы и гипотеза о миграции населения ямной культуры в Центральную Европу.
|
Продолжаем публиковать статью археологов из Одесского университета проф. С.В. Ивановой и к.и.н. Д.В. Киосака и археогенетика, проф. Grand Valley State University А.Г. Никитина. Предмет исследования - археологическая и культурная картина Северо-Западного Причерноморья эпохи энеолита - ранней бронзы и гипотеза о миграции населения ямной культуры в Центральную Европу.
|
Представляем статью крупнейшего специалиста по степным культурам, проф. Одесского университета С.В. Ивановой, археолога из Одесского университета Д.В. Киосака и генетика, работающего в США, А.Г. Никитина. В статье представлена археологическая и культурная картина Северо-Западного Причерноморья эпохи энеолита - ранней бронзы и критический разбор гипотезы о миграции населения ямной культуры в Центральную Европу. Публикуем статью в трех частях.
|
Новые детали взаимоотношений современного человека с неандертальцами получены по анализу митохондри альной ДНК неандертальца из пещеры в Германии. Предложенный авторами сценар ий предполагает раннюю миграцию предков сапиенсов из Африки в Европу, где они метисировались с неандертальцами, оставив им в наследство свою мтДНК.
|
Изучив митохондриальную ДНК древних и современных армян, генетики делают вывод о генетической преемственности по материнским линиям наследования в популяциях Южного Кавказа в течение 8 тысяч лет. Многочисленные культурные перемены, происходящие за это время, не сопровождались изменениями в женской части генофонда.
|
Исследование генофонда парсов – зороастрийцев Индии и Пакистана – реконструировало их генетическую историю. Парсы оказались генетически близки к неолитическим иранцам, так как покинули Иран еще до исламизации. Несмотря на преимущественное заключение браков в своей среде, переселение в Индию оставило генетический след в популяции парсов. Оно сказалось в основном на их митохондриальном генофонде за счет ассимиляции местных женщин.
|
На прошедшем форуме «Ученые против мифов-4», организованном порталом «Антропогенез.ру», состоялась специальная конференция «Ученые против мифов-профи» - для популяризаторов науки. В профессиональной среде обсуждались способы, трудности и перспективы борьбы с лженаукой и популяризации науки истинной.
|
С разрешения авторов публикуем диалог д.и.н. Александра Григорьевича Козинцева и проф. Льва Самуиловича Клейна, состоявшийся в мае 2017 г.
|
С разрешения автора и издательства перепечатываем статью доктора историч. наук А.Г.Козинцева, опубликованную в сборнике, посвященном 90-летию Л.С.Клейна (Ex ungue leonem. Сборник статей к 90-летию Льва Самуиловича Клейна. СПб: Нестор-история, 2017. С.9-12).
|
Конференция «Позднепалеолитические памятники Восточной Европы», состоявшаяся в НИИ и Музее Антропологии МГУ, была посвящена 100-летию со дня рождения Марианны Давидовны Гвоздовер (1917-2004) – выдающегося археолога, специалиста по палеолиту. Участники конференции с большой теплотой вспоминали ее как своего учителя, а тематика докладов отражала развитие ее идей.
|
В журнале Science опубликованы размышления о роли исследований древней ДНК в представлениях об истории человечества и о непростых взаимодействиях генетиков с археологами. Одна из основных сложностей заключается в неоднозначных связях между популяциями и археологическими культурами. Решение сложных вопросов возможно только путем глубокой интеграции генетики, археологии и других наук.
|
По 367 митохондриальным геномам построено дерево гаплогруппы U7, определена ее прародина и описано распространение основных ветвей. Некоторые из них связывают с демографическими событиями неолита.
|
Казахские, российские и узбекские генетики исследовали генофонд населения исторического региона Центральной Азии – Трансоксианы по маркерам Y-хромосомы. Оказалось, что основную роль в структурировании генофонда Трансоксианы играет не географический ландшафт, а культура (хозяйственно-культурный тип): земледелие или же кочевое скотоводство. Показано, что культурная и демическая экспансии могут быть не взаимосвязаны: экспансия арабов не оказала значимого влияния на генофонд населения Трансоксианы, а демическая экспансия монголов не оказала значимого влияния на его культуру.
|
Российские антропологи исследовали особенности морфологии средней части лица в популяциях Северо-Восточной Европы в связи с факторами климата. Оказалось, что адаптации к низким температурам у них иные, чем у народов Северной Сибири. Полученные результаты помогут реконструировать адаптацию к климату Homo sapiens верхнего палеолита, так как верхнепалеолитический климат был более всего похож на современный климат Северо-Восточной Европы. Таким образом, современные северо-восточные европейцы могут послужить моделью для реконструкции процессов, происходивших десятки тысяч лет назад.
|
Немецкие генетики успешно секвенировали митохондриальную и проанализировали ядерную ДНК из египетских мумий разных исторических периодов. Они показали, что древние египтяне были генетически близки к ближневосточному населению. Современные египтяне довольно сильно отличаются от древних, главным образом долей африканского генетического компонента, приобретенного в поздние времена.
|
Данные по четырем древним геномам из бассейна Нижнего Дуная указали на долгое мирное сосуществование местных охотников-собирателей и мигрировавших земледельцев в этом регионе. На протяжении нескольких поколений между ними происходило генетическое смещение, а также передача культурных навыков.
|
Цвет кожи человека сформировался под сильным давлением естественного отбора и определяется балансом защиты от ультрафиолета и необходимого уровня синтеза витамина D. Цвет волос и радужной оболочки глаза, хотя в основном определяется тем же пигментом, в меньшей степени продукт естественного отбора и находится под большим влиянием других факторов. Одни и те же гены могут влиять на разные пигментные системы, а комбинация разных аллелей может давать один и тот же результат.
|
Юго-Восточная Европа в неолите служила местом интенсивных генетических и культурных контактов между мигрирующими земледельцами и местными охотниками-собирателями, показывает исследование 200 древних геномов из этого региона. Авторы описали разнообразие европейских охотников-собирателей; нашли, что не все популяции, принесшие земледелие в Европу, происходят из одного источника; оценили долю степного компонента в разных группах населения; продемонстрировали, что в смешении охотников-собирателей с земледельцами имел место гендерный дисбаланс – преобладание мужского вклада от первых.
|
Культурная традиция колоковидных кубков (одна из самых широко распространенных культур в позднем неолите/бронзовом веке), по-видимому, распространялась по Европе двумя способами – как передачей культурных навыков, так и миграциями населения. Это выяснили палеогенетики, представив новые данные по 170 древним геномам из разных регионов Европы. В частности, миграции с континентальной Европы сыграли ведущую роль в распространении ККК на Британские острова, что привело к замене 90% генофонда прежнего неолитического населения.
|
Российские антропологи провели новое исследование останков человека с верхнепалеолитической стоянки Костёнки-14 с использованием современных статистических методов анализа. Они пришли к выводу о его принадлежности к европеоидному типу и отсутствии австрало-меланезийских черт в строении черепа и зубной системы. Примечательно, что этот вывод согласуется с данными палеогенетиков.
|
Профессор Тоомас Кивисилд, один из ведущих геномных специалистов, представляющий Кембриджский университет и Эстонский биоцентр, опубликовал обзор по исследованиям Y-хромосомы из древних геномов. В этой обобщающей работе он сфокусировался на данных по Y-хромосомному разнообразию древних популяций в разных регионах Северной Евразии и Америки.
|
С разрешения редакции публикуем статью д.и.н. О.В.Шарова (Институт истории материальной культуры РАН) о роли выдающегося археолога д.и.н. М. Б. Щукина в решении проблемы природы черняховской культуры. В следующих публикациях на сайте можно будет познакомиться непосредственно с трудами М. Б. Щукина.
|
Перепечатываем статью выдающегося археолога М.Б.Щукина «Рождение славян», опубликованную в 1997 г. в сборнике СТРАТУМ: СТРУКТУРЫ И КАТАСТРОФЫ. Сборник символической индоевропейской истории. СПб: Нестор, 1997. 268 с.
|
Ученым удалось выделить древнюю мтДНК, в том числе неандертальцев и денисовцев, из осадочных отложений в пещерах, где не сохранилось самих костей. Авторы считают, что этот способ может значительно увеличить количество древних геномов.
|
Авторы находки в Южной Калифорнии считают, что метки на костях мастодонта и расположение самих костей говорят о следах человеческой деятельности. Датировка костей показала время 130 тысяч лет назад. Могли ли быть люди в Северной Америке в это время? Кто и откуда? Возникают вопросы, на которые нет ответов.
|
Представляем обзор статьи британского археолога Фолкера Хейда с критическим осмыслением последних работ палеогенетиков с археологических позиций.
|
Публикуем полную печатную версию видеоинтревью, которое несколько месяцев назад Лев Самуилович Клейн дал для портала "Русский материалист".
|
И снова о ямниках. Археолог Кристиан Кристиансен о роли степной ямной миграции в формировании культуры шнуровой керамики в Европе. Предлагаемый сценарий: миграция мужчин ямной культуры в Европу, которые брали в жены местных женщин из неолитических общин и формировали культуру шнуровой керамики, перенимая от женщин традицию изготовления керамики и обогащая протоиндоевропейский язык земледельческой лексикой.
|
Анализ древней ДНК из Эстонии показал, что переход от охоты-рыболовства-собирательства к сельскому хозяйству в этом регионе был связан с прибытием нового населения. Однако основной вклад внесла не миграция неолитических земледельцев из Анатолии (как в Центральной Европе), а миграция бронзового века из степей. Авторы пришли к выводу, что степной генетический вклад был, преимущественно, мужским, а вклад земледельцев Анатолии – женским.
|
Российские генетики изучили по Y-хромосоме генофонд четырех популяций коренного русского населения Ярославской области. Результаты указали на финно-угорский генетический след, но вклад его невелик. Наиболее ярко он проявился в генофонде потомков жителей города Молога, затопленного Рыбинским водохранилищем, что подтверждает давнюю гипотезу об их происхождении от летописных мерян. В остальных популяциях финно-угорский генетический пласт был почти полностью замещен славянским. Причем результаты позволяют выдвинуть гипотезу, что славянская колонизация шла преимущественно по «низовому» ростово-суздальскому пути, а не по «верховому» новгородскому.
|
Публикуем официальный отзыв д.ф.н. и д.и.н., проф. С.П.Щавелева на диссертацию и автореферат диссертации И.П. Лобанковой «Пассионарность в динамике культуры: философско-методологическая реконструкция культуры протогорода Аркаим», представленной на соискание ученой степени доктора философских наук.
|
В коротком сообщении, появившемся на сайте препринтов, его авторы – Иосиф Лазаридис и Дэвид Райх (Медицинская школа Гарварда), опровергают вывод, опубликованный недавно в статье Goldberg et al., о которой мы писали на сайте.
|
Продолжаем ответ на "этнический портрет среднестатистического россиянина" от компании "Генотек" . Часть третья, от специалиста по генетической генеалогии и блогера Сергея Козлова.
|
Продолжаем публиковать ответ на "этнический портрет среднестатистического россиянина" от компании "Генотек" . Часть вторая, от генетика, д. б. н., профессора Е.В.Балановской.
|
Публикуем наш ответ на опубликованный в массовой печати "этнический портрет среднестатистического россиянина" от компании "Генотек" . Часть первая.
|
Размещаем на сайте препринт статьи, предназначенной для Acta Archaeologica (Kopenhagen), для тома, посвященного памяти выдающегося датского археолога Клауса Рандсборга (1944 – 2016), где она будет опубликована на английском языке.
|
Известнейший российский археолог Лев Клейн написал две новые книги. Как не потерять вдохновение в работе над книгой? Когда случилось ограбление века? И что читать, если хочешь разбираться в археологии? Лев Самуилович отвечает на вопросы корреспондента АНТРОПОГЕНЕЗ.РУ
|
Публикуем комментарий проф. Л.С.Клейна на докторскую диссертацию И.П. Лобанковой «Пассионарность в динамике культуры: Философско-методологическая реконструкция культуры протогорода Аркаим».
|
Российские генетики исследовали генофонд народов Передней Азии и нашли интересную закономерность: наиболее генетически контрастны народы, живущие в горах и на равнине. Оказалось, что большинство армянских диаспор сохраняет генофонд исходной популяции на Армянском нагорье. По данным полного секвенирования 11 Y-хромосом авторы построили филогенетическое дерево гаплогруппы R1b и обнаружили на этом дереве помимо известной западноевропейской новую восточноевропейскую ветвь. Именно на ней разместились варианты Y-хромосом степных кочевников ямной культуры бронзового века. А значит, не они принести эту мужскую линию в Западную Европу.
|
В издательстве ЕВРАЗИЯ в Санкт-Петербурге вышла научно-популярная книга проф. Льва Самуиловича Клейна "Первый век: сокровища сарматских курганов". Она посвящена двум самым выдающимся памятникам сарматской эпохи нашей страны — Новочеркасскому кладу (курган Хохлач) и Садовому кургану.
|
Исследуя останки из захоронений степных кочевников железного века – скифов – методами краниометрии (измерение параметров черепов) и методами анализа древней ДНК, антропологи и генетики пришли к сопоставимым результатам. Те и другие специалисты обнаруживают близость кочевников культуры скифов к культурам кочевников бронзового века Восточной Европы. Антропологическими и генетическими методами у носителей скифской культуры выявляется также центральноазиатский (антропологи) либо восточноазиатско-сибирский (генетики) вклад. Что касается прародины скифов – европейские или азиатские степи – то по этому вопросу специалисты пока не пришли к единому мнению.
|
Древняя ДНК может рассказать не только о миграциях и демографической истории наших предков, но и о социальном устройстве общества. Пример такого исследования – работа генетиков из Университета Пенсильвании, опубликованная в журнале Nature Communication.
|
Представляем сводку археологических культур, представленных на страницах Словарика. Пока - список по алфавиту.
|
Публикуем статью Сергея Козлова с результатами анализа генофондов некоторых северных народов в свете данных из монографии В.В.Напольских "Очерки по этнической истории".
|
Анализ митохондриальной ДНК представителей трипольской культуры Украины показал ее генетическое происхождение по материнским линиям от неолитических земледельцев Анатолии с небольшой примесью охотников-собирателей верхнего палеолита. Популяция трипольской культуры из пещеры Вертеба генетически сходна с другими популяциями европейских земледельцев, но более всего – с популяциями культуры воронковидных кубков.
|
Анализ древней ДНК мезолита и неолита Балтики и Украины не выявил следов миграции земледельцев Анатолии, аналогичный найденным в неолите Центральной Европы. Авторы работы предполагают генетическую преемственность от мезолита к неолиту в обоих регионах. Они также нашли признаки внешнего влияния на генофонд позднего неолита, наиболее вероятно, это вклад миграции из причерноморских степей или из Северной Евразии. Определенно, неолит как в регионе Балтики, так и на Днепровских порогах (Украина) развивался иными темпами, чем в Центральной и Западной Европе, и не сопровождался такими масштабными генетическими изменениями.
|
Рассказ о генетико-антропологической экспедиции Медико-генетического научного центра и Института общей генетики РАН, проведенной в конце 2016 года в Тверскую область для исследования генофонда и создания антропологического портрета тверских карел и тверских русских.
|
Изучив митохондриальную ДНК из погребений энеолита и бронзового века в курганах Северного Причерноморья, генетики сделали вывод о генетической связи популяций степных культур с европейскими мезолитическими охотниками-собирателями.
|
9 января исполнился год со дня скоропостижной смерти смерти археолога и этнографа Владимира Александровича Кореняко, ведущего научного сотрудника Государственного музея искусства народов Востока, одного из авторов нашего сайта. С разрешения издательства перепечатываем его статью об этнонационализме, которая год назад была опубликована в журнале "Историческая экспертиза" (издательство "Нестор-история").
|
1 февраля на Биологическом факультете МГУ прошло Торжественное заседание, посвященное 125-летию со дня рождения Александра Сергеевича Серебровского, русского и советского генетика, члена-корр. АН СССР, академика ВАСХНИЛ, основателя кафедры генетики в Московском университете.
|
В совместной работе популяционных генетиков и генетических генеалогов удалось построить филогенетическое дерево гаплогруппы Q3, картографировать распределение ее ветвей, предположить место ее прародины и модель эволюции, начиная с верхнего палеолита. Авторы проследили путь ветвей гаплогруппы Q3 от Западной и Южной Азии до Европы и конкретно до популяции евреев ашкенази. Они считают, что этот удачный опыт послужит основой для дальнейшего сотрудничества академической и гражданской науки.
|
В конце ноября прошлого года в Москве прошла Всероссийская научная конференция «Пути эволюционной географии», посвященная памяти профессора Андрея Алексеевича Величко, создателя научной школы эволюционной географии и палеоклиматологии. Конференция носила междисциплинарный характер, многие доклады были посвящены исследованию географических факторов расселения человека по планете, его адаптации к различным природным условиям, влиянию этих условий на характер поселений и пути миграции древнего человека. Представляем краткий обзор некоторых из этих междисциплинарных докладов.
|
Публикуем статью Сергея Козлова о структуре генофонда Русского Севера, написанную по результатам анализа полногеномных аутосомных данных, собранных по научным и коммерческим выборкам.
|
В журнале Science Advances опубликованы результаты исследования геномов двух индивидов из восточноазиатской популяции эпохи неолита. Определено их генетическое сходство с ныне живущими популяциями. До сих пор исследования древней ДНК очень мало затрагивали регион Восточной Азии. Новые данные были получены при исследовании ДНК из останков двух женщин, найденных в пещере «Чертовы ворота» в Приморье, их возраст составляет около 7700 лет. Эти индивиды принадлежали к популяции охотников-рыболовов-собирателей, без каких-либо признаков производящего хозяйства, хотя было показано, что из волокон диких растений они изготавливали текстиль.
|
Обзор истории заселения всего мира по данным последних исследований современной и древней ДНК от одного из самых известных коллективов палеогенетиков под руководством Эске Виллерслева. Представлена картина миграций в глобальном масштабе, пути освоения континентов и схемы генетических потоков между человеком современного типа и древними видами человека.
|
Изучение Y-хромосомных портретов крупнейшей родоплеменной группы казахов в сопоставлении с данными традиционной генеалогии позволяет выдвинуть гипотезу, что их генофонд восходит к наследию народов индоиранской языковой семьи с последующим генетическим вкладом тюркоязычных и монголоязычных народов. Вероятно, основным родоначальником большинства современных аргынов был золотоордынский эмир Караходжа (XIV в.) или его ближайшие предки.
|
Путем анализа Y-хромосомных и аутосомных данных современного населения Юго-Западной Азии генетики проследили пути, по которым шло заселение этой территории после окончания Последней ледниковой эпохи. Они выделили три климатических убежища (рефугиума), которые стали источником миграций в регионе, и определили время расхождения ветвей Y-хромосомы в популяциях. Полученные результаты авторы обсуждают в связи с археологическими данными и работами по древней ДНК.
|
Генетики секвенировали четыре генома Yersinia pestis эпохи бронзового века. Их сравнение с другими древними и современными геномами этой бактерии привело к гипотезе, что чума в Европе появилась со степной миграцией ямной культуры, а затем вернулась обратно в Центральную Азию.
|
Исследование показало, что подавляющее большинство американских антропологов не считают расы биологической реальностью, не видят в расовой классификации генетической основы и не считают, что расу нужно учитывать при диагностике и лечении заболеваний. Сравнение показало, что антропологов, не признающих расы, в 2013 году стало радикально больше, чем 40 лет назад. Cтатья с результатами этого исследования опубликована в American Journal of Physical Anthropology.
|
Отзыв проф. Л.С.Клейна о книге Д.В.Панченко «Гомер, „Илиада”, Троя», вышедшей в издательстве «Европейский Дом».
|
В конце уходящего 2016 года попробуем подвести его итоги – вспомнить самые интересные достижения на перекрестке наук, изучающих историю народонаселения – археологии, антропологии, генетики, палеогеографии, лингвистики и др. Конечно, наш взгляд субъективен, поскольку мы смотрим через окно сайта «Генофонд.рф», ориентируясь на опубликованные на нем материалы. По той же причине в научных итогах мы вынужденно делаем крен в генетику. Будем рады если эта картина станет полнее с помощью комментариев от наших читателей.
|
Коллектив генетиков и историков изучил генофонды пяти родовых объединений (кланов) северо-восточных башкир. Преобладание в их Y-хромосомных «генетических портретах» одного варианта гаплогрупп указывает на единый генетический источник их происхождения – генофонд прото-клана. Выдвинута гипотеза, что формирование генофонда северо-восточных башкир связано с трансуральским путем миграций из Западной Сибири в Приуралье, хорошо известном кочевникам в эпоху раннего железного века и средневековья.
|
Перепечатываем статью О.П.Балановского, опубликованную татарским интернет-изданием "Бизнес-онлайн" - ответ критикам исследования генофондов татар.
|
Изучение Y-хромосомных генофондов сибирских татар выявило генетическое своеобразие каждого из пяти субэтносов. По степени различий между пятью популяциями сибирские татары лидируют среди изученных коллективом народов Сибири и Центральной Азии. Результаты позволяют говорить о разных путях происхождения генофондов сибирских татар (по данным об отцовских линиях): в каждом субэтносе проявляется свой субстрат (вклад древнего населения) и свой суперстрат (влияние последующих миграций).
|
Дискуссия, вызванная статьей о генофонде татар в "Вестнике МГУ", вылилась на страницы интернет-издания "Бизнес-онлайн". Публикуем письмо, отправленное д.б.н., профессором РАН О.П. Балановским 17 декабря 2016 года одному из участников этой дискуссии, д.и.н., специалисту по этногенезу татарского народа И.Л.Измайлову. Письмо, к сожалению, осталось без ответа.
|
Исследование Y-хромосомы туркменской популяции в Каракалпакстане (на территории Узбекистана) выявило сильное доминирование гаплогруппыQ, что, вероятно, объясняется их преобладающей принадлежностью к одному роду (йомуд). По генетическим расстояниям туркмены Каракалпакстана оказались близки к географически далеким от них туркменам Ирана и Афганистана и далеки от своих географических соседей – узбеков и каракалпаков.
|
Генофонды популяций с этнонимом «татары» трех регионов Евразии - крымские, поволжские и сибирские – исследованы путем анализа Y-хромосомы. Этнотерриториальные группы татар оказались генетически очень разнообразны. В генофонде поволжских татар преобладают генетические варианты, характерные для Приуралья и Северной Европы; в генофонде крымских татар преобладает вклад переднеазиатского и средиземноморского населения; популяции сибирских татар наиболее разнообразны: одни включают значительный сибирский генетический компонент, в других преобладают генетические линии из юго-западных регионов Евразии.
|
Популяционно-генетическую историю друзов британский генетик Эран Элхаик исследует методом GPS (geographic population structure). Критика специалистов в адрес предыдущих работ с использованием данного метода, вызывает вопросы и к данной работе.
|
Опубликовано на сайте Антропогенез.ру
|
В пределах 265 языковых семей исследователи показали корреляцию между лексикой разных языков и географическим положением. На примере 11 популяций из Африки, Азии и Австралии выявили корреляцию лексических расстояний между популяциями с фенотипическими расстояниями, самую высокую – по строению лицевой части черепа. Делается вывод о том, что лингвистические показатели можно использовать для реконструкции недавней истории популяций, но не глубокой истории.
|
Представляяем обзор некоторых докладов на прошедшей в Москве конференции «Эволюционный континуум рода Homo», посвященной 125-летию со дня рождения выдающегося русского антрополога Виктора Валериановича Бунака (1891–1979), иными словами, на Бунаковских чтениях.
|
Из-за чего случился бронзовый коллапс, как исчезла знаменитая майкопская культура, в чём заблуждаются сторонники «новой хронологии» и какие байки живут среди археологов, порталу АНТРОПОГЕНЕЗ.РУ рассказал Александр Скаков - кандидат исторических наук, научный сотрудник Отдела бронзового века Института археологии РАН.
|
В Москве завершила свою работу международная антропологическая конференция, посвященная 125-летию выдающегося русского антрополога Виктора Валериановича Бунака. Приводим краткий обзор ее итогов, опубликованный на сайте Центра палеоэтнологических исследований.
|
К сожалению, эхо от казанского интервью академика Валерия Александровича Тишкова (директора Института этнологии и антропологии РАН) не затихло, а рождает все новые недоразумения, которые отчасти уже объяснены на нашем сайте. Чтобы приостановить снежный ком, нам все же придется дать разъяснения неточностей, его породивших.
|
Статья американских и шведских исследователей (Goldberg et al.), опубликованная на сайте препринтов, вновь обращается к дискуссионной проблеме миграций в эпоху неолита и бронзового века. В работе исследуется вопрос о доле мужского и женского населения в составе мигрирующих групп, которые сформировали генофонд Центральной Европы. Авторы проверяют исходную гипотезу, что миграции из Анатолии в раннем неолите и миграции из понто-каспийских степей в течение позднего неолита и бронзового века были преимущественно мужскими.
|
Специалист по этногенезу тюркских народов Жаксылык Сабитов комментирует миф о финно-угорском происхождении татар, который без всяких на то оснований приписывается генетикам.
|
О.П.Балановский о том, как проходило обсуждение доклада А.В.Дыбо «Происхождение и родственные связи языков народов России» на Президиуме РАН.
|
Публикуем изложение доклада чл-корр. РАН Анны Владимировны Дыбо (Институт языкознания РАН), размещенное на сайте РАН.
|
Полное секвенирование геномов 83 австралийских аборигенов и 25 жителей Папуа Новая Гвинея позволило исследователям реконструировать историю заселения этой части света в пространстве и во времени. Они подтвердили, что предки австралийских аборигенов и папуасов Новой Гвинеи очень рано отделились от предков материковой Евразии. На ключевой вопрос о том, сколько раз человечество выходило из Африки – один или два, авторы отвечают с осторожностью. Большая часть их аргументов склоняет чашу весов к модели одного выхода, однако тот вариант, что их могло быть два, исследователи не отвергают.
|
Прочитав с высокой степенью надежности 379 геномов из 125 популяций со всего мира, исследователи уточнили картину современного генетического разнообразия и пути древних миграций, которые к нему привели. В частности, в геномах папуасов Новой Гвинеи они нашли небольшой вклад ранней миграционной волны из Африки, которая не оставила следов в геномах материковой Евразии.
|
Полное секвенирование 300 геномов из 142 популяций со всего мира дало возможность исследователям добавить важные фрагменты в мозаику геномного разнообразия населения планеты. Они пересчитали вклад неандертальцев и денисовцев в современный геном в глобальном масштабе, вычислили, как давно разошлись между собой разные народы, оценили степень гетерозиготности в разных регионах. Наконец, авторы уточнили источник генофонда жителей Австралии и Новой Гвинеи, показав, что они происходят от тех же популяций, что и жители остальной Евразии.
|
Приводим экспертное мнение Жаксылыка Сабитова (Евразийский Национальный Университет, Астана), специалиста по истории Золотой орды и этногенезу тюркских народов, по недавно опубликованной в журнале PLоS ONE статье .
|
В журнале PLOS Genetics опубликованы результаты широкогеномного (в пределах всего генома) исследования ассоциаций (GWAS) различных черт лица. У 3118 жителей США европейского происхождения авторы провели трехмерное измерение 20 лицевых признаков и анализ однонуклеотидного полиморфизма (около 1 млн SNP). Обнаружили достоверную связь полиморфных участков генома с шириной черепа, шириной расстояния между внутренними углами глаз, шириной носа, длиной крыльев носа и глубиной верхней части лица.
|
Коллектив генетиков и биоинформатиков опубликовал обзор истории изучения древней ДНК, основных трудностей в ее изучении и методов их преодоления. Авторы представили новейшие знания о путях миграций и распространения населения, полученные путем анализа древних геномов, и показали, какую революционную роль анализ палеоДНК сыграл в популяционной и эволюционной генетике, археологии, палеоэпидемиологии и многих других науках.
|
Проект по секвенированию более 60 тысяч экзомов (часть генома, кодирующая белки) в популяциях на разных континентах выявил гены, устойчивые к мутированию, показал, сколько носимых нами мутаций полностью блокируют синтез белка, а также значительно приблизил специалистов к пониманию природы редких заболеваний.
|
Российские генетики определили полную последовательность шести митохондриальных геномов древних людей, обитавших на территории Северного Кавказа на рубеже неолита и бронзы.
|
Сравнив фенотипические расстояния между 10 популяциями по показателям формы черепа и генетические расстояния по 3 345 SNP, исследователи нашли корреляции между ними. Они утверждают, что форма черепа в целом и форма височных костей может быть использована для реконструкции истории человеческих популяций.
|
Изучен генофонд популяции польско-литовских татар (липок), проживающих в Белоруссии. В их генофонде примерно две трети составляет западноевразийский компонент и одну треть – восточноевразийский. Очевидно, последний отражает влияние дальних миграций – степных кочевников Золотой Орды, поселившихся в Центральной и Восточной Европе.
|
Лингвисты из Кембриджского и Оксфордского университетов, разработали технологию, которая, как они утверждают, позволяет реконструировать звуки праиндоевропейского языка. Сообщение об этом опубликовано на сайте Кембриджского университета http://www.cam.ac.uk/research/features/time-travelling-to-the-mother-tongue.
|
Перепечатываем статью Павла Флегонтова и Алексея Касьяна, опубликованную в газете "Троицкий вариант", с опровержением гипотезы английского генетика Эрана Элхаика о хазарском происхождении евреев ашкеназов и славянской природе языка идиш. Эта популярная статья вышла параллельно с научной статьей с участием этих же авторов в журнале Genome Biology and Evolution.
|
15 июля в Еженедельной газете научного сообщества "Поиск" опубликовано интервью с О.П. Балановским. Подробности по ссылке:
|
Турсервис Momondo сделал генетические тесты и записал реакцию на их результаты. Видео получилось простым и понятным. А что думает об этом популяционная генетика?
|
В только что опубликованной статье была подробно изучена история распространения одной из самых широко встречающихся в Евразии Y-хромосомных гаплогрупп – N. По данным полного секвенирования Y-хромосомы было построено филогенетическое дерево и описано подразделение гаплогруппы на ветви и субветви. Оказалось, что большинство из них имеют точную географическую но не лингвистическую привязку (встречаются в популяциях различных языковых семей).
|
Новое исследование генетических корней евреев ашкеназов подтвердило смешанное европейско-ближневосточное происхождение популяции. В составе европейского предкового компонента наиболее существенный генетический поток ашкеназы получили из Южной Европы.
|
Опубликована единственная на настоящий момент работа, посвященная исследованию генофонда верхнедонских казаков. Для изучения генофонда казаков использован новый инструмент - программа Haplomatch, позволяющая производить сравнение целых массивов гаплотипов. Удалось проследить, что формирование генофонда казаков верхнего Дона шло преимущественно за счет мигрантов из восточно-славянских популяций (в частности с южно-, центрально - русских и украинцев). Также обнаружено небольшое генетическое влияние ногайцев, вероятно вызванное их вхождением в Войско Донское в составе «татарской прослойки». Сходства с народами Кавказа у донских казаков не обнаружено.
|
Публикуем перевод статьи Душана Борича и Эмануэлы Кристиани, в которой рассматриваются социальные связи между группами собирателей палеолита и мезолита в Южной Европе (на Балканах и в Италии). Социальные связи прослеживаются в том числе путем исследования и сопоставления технологий изготовления орудий и украшений.
|
Используя традиционные подходы и свой собственный новый метод, специалисты изучили происхождение коренных народов Сибири. Для популяций Южной Сибири, они реконструировали последовательность генетических потоков, которые смешивались в генофонде.
|
Анализ древней ДНК с Ближнего Востока показал, что большой вклад в генофонд первых ближневосточных земледельцев внесла древняя линия базальных евразийцев; что в пределах Ближнего Востока популяции земледельцев генетически различались по регионам, и между охотниками-собирателями и первыми земледельцами в каждом регионе имелась генетическая преемственность.
|
Представляем обобщающую статью по культурам верхнего палеолита, которая может служить пояснением для соответствующих статей в Словарике, посвященных отдельным культурам верхнего палеолита.
|
Форум «Ученые против мифов», организованный порталом «Антропогенез.ру», прошел в Москве 5 июня. Организаторы обещают скоро выложить записи докладов. Пока же представляем основные тезисы, прозвучавшие в выступлениях участников форума.
|
Анализ древней и современной ДНК собак, включая полностью секвенированный древний геном неолитической собаки из Ирландии и 605 современных геномов, привел исследователей к гипотезе, что человек независимо одомашнил волка в Восточной Азии и в Европе. Затем палеолитическая европейская популяция собак была частично замещена восточноазиатскими собаками.
|
Митохондриальная ДНК человека возрастом 35 тыс. лет назад из пещеры в Румынии оказалась принадлежащей к африканской гаплогруппе U6. Из этого исследователи сделали вывод о евразийском происхождении этой гаплогруппы и о том, что она была принесена в Северную Африку путем верхнепалеолитической обратной миграции.
|
Археологи провели исследование загадочных конструкций в форме кольца из обломков сталагмитов в пещере Брюникель на юго-западе Франции. Особенности конструкций, следы огня на них и соседство с костями говори т об их рукотворном происхождении. Датировка - 176.5 тысяч лет назад – указала на ранних неандертальцев.
|
Cпециалисты нашли шесть генов, вариации в которых влияют на черты лица человека. Все они экспрессируются при эмбриональной закладке лицевой части черепа, влияя на дифференцировку клеток костной и хрящевой ткани. Больше всего генетические вариации связаны с параметрами носа.
|
С разрешения автора перепечатываем статью доктора истор. наук Виктора Александровича Шнирельмана "Междисциплинарный подход и этногенез", опубликованную в сборнике "Феномен междисциплинарности в отечественной этнологи" под ред Г. А. Комаровой, М.: ИЭА РАН, 2016. С. 258-284.
|
Исследование показало, что популяция Бене-Исраэль, живущая в Индии, имеет смешанное еврейско-индийское происхождение. Причем вклад евреев передался в основном по мужским линиям наследования (по Y-хромосоме), а вклад индийцев – по женским (по мтДНК). Время же возникновения популяции оказалось не столь давним, как в легендах.
|
Пещера Шове известна во всем мире наскальными рисунками эпохи палеолита. Древние художники использовали ее для своего творчества в два этапа с перерывом. Причем один из этих этапов перекрывался по времени с периодом обитания здесь пещерных медведей. Авторы нового исследования реконструировали историю обитания пещеры, используя многочисленные датировки и моделирование.
|
История генофонда Европы до неолитизации очень мало изучена. Новое исследование под руководством трех лидеров в области древней ДНК приоткрывает дверь в события более далекого прошлого. Авторы проанализировали 51 образец древней ДНК и частично реконструировали картину движения популяций до и после Последнего ледникового максимума. Они попытались связать обнаруженные ими генетические кластеры, объединяющие древних индивидов в пространстве и во времени, с определенными археологическими культурами.
|
Новый метод молекулярно-генетической датировки, предложенный в статье команды Дэвида Райха, основан на сравнении древних и современных геномов по длине неандертальских фрагментов ДНК. В отличие от радиоуглеродной датировки, этот метод точнее работает на более старых образцах. С его помощью авторы также вычислили длину поколения (26-30 лет), предположив, что она существенно не менялась за 45 тысячелетий.
|
По рекордному на сегодняшний день количеству полностью секвенированных Y-хромосом (1244 из базы проекта «1000 геномов») исследователи построили новое разветвленное Y-хромосомное дерево и попытались связать экспансию отдельных гаплогрупп с историческими сведениями и археологическими данными.
|
Палитра геномных исследований в России разнообразна. Создаются генетические биобанки, исследуется генетическое разнообразие популяций, в том числе генетические варианты, связанные с заболеваниями в разных популяциях; российские специалисты вовлечены в полногеномные исследования, и на карте мира постепенно появляются секвенированные геномы из России.
|
Исследователи секвенировали геномы из Меланезии и нашли у них наибольшую долю включений ДНК древних видов человека, причем как неандертальского, так и денисовского происхождения. Новые данные позволили нарисовать уточненную картину генетических потоков между разными видами Homo.
|
С разрешения автора публикуем тезисы его доклада на предстоящей конференции в Томске.
|
Представляем перевод статьи североирландского и американского археолога, специалиста по индоеропейской проблематике, профессора Джеймса Патрика Мэллори. Эта статья представляет собою обобщающий комментарий к некоторым докладам на семинаре «Прародина индоевропейцев и миграции: лингвистика, археология и ДНК» (Москва, 12 сентября 2012 года).
|
Исследователи из Стэнфордского университета, проанализировав Y-хромосому неандертальцев, убедились в том, что в Y-хромосоме современного человека нет неандертальских фрагментов ДНК, в отличие от остальной части генома. Этому факту они постарались дать объяснение. Скорее всего, дело в антигенах гистосовместимости, которые препятствовали рождению мальчиков с неандертальскими генами в Y-хромосоме.
|
Исследовав 92 образца древней мтДНК коренных американцев, генетики реконструировали основные этапы заселения Америки, уточнив пути основных миграций и их время. Они также пришли к выводу о драматическом влиянии европейской колонизации на генетическое разнообразие коренного населения Америки.
|
Публикуем перевод критической статьи известного болгарского археолога Лолиты Николовой. Ее критика направлена на авторов одной из самой яркой статьи прошлого года «Massive migration from the steppes was a source for Indo-European Languages in Europe» (Haak et al., 2015), в которой авторы представляют свою гипотезу распространения индоевропейских языков в Европе.
|
Публикуем статью украинского археолога, доктора ист. наук, проф. Леонида Львовича Зализняка, специально переведенную им на русский язык для нашего сайта. Статья представляет собой критический анализ взглядов на происхождение индоевропейцев с позиций археологии и других наук.
|
Перепечатываем статью швейцарского лингвиста Патрика Серио, перевод которой был опубликован в журнале «Политическая лингвистика». В статье анализируется явление «Новой парадигмы» в области лингвистики в странах Восточной Европы. С точки зрения автора, это явление подходит под определение ресентимента.
|
Человек (Homo sapiens) – единственное в природе существо, которое может переносить из сознания на внешние носители фигуративные образы. В эволюции нет ничего, что бы предшествовало этой способности. Таким же уникальным свойством является способность к членораздельной речи, к языку. Звуковые сигналы в мире других живых существ заданы генетически. Возникает предположение, что эти две способности связаны между собой больше, чем нам кажется.
|
Генетический анализ популяции кетов – коренного народа Сибири, в сравнении с окружающим народами в бассейне Енисея выявил их наиболее тесную связь с карасукской культурой бронзового века Южной Сибири - именно в этом регионе находится гипотетическая прародина енисейской семьи языков. Более глубокие корни кетов уходят к ветви древних северных евразийцев. По опубликованным ранее и по новым данным, 5000-6000 лет назад генетический поток протянулся от сибирских популяций до культуры саккак (палеоэскимосов американской Арктики), и от саккак к носителям языков на-дене. Примечательно, что данная миграция согласуется с гипотезой о родстве енисейских языков и языков на-дене.
|
История взаимоотношений человека современного вида и неандертальцев оказалась непростой и долгой. Не только неандертальцы оставили след в нашем геноме. Обнаружен генетический поток и от Homo sapiens к предкам алтайских неандертальцев. Он указывает на раннюю - около 100 тысяч лет назад - метисацию, что происходила еще до основной волны выхода наших предков из Африки.
|
Статья является реакцией на публикацию коллектива американских авторов, отрицающих существование рас у человека и, более того, призывающих отменить и запретить использование самого термина «раса». Авторы обнаруживают полное незнание предмета обсуждения и научной литературы по проблеме расы. «Антирасовая кампания», уже давно развязанная в США и перекинувщаяся в научные центры Западной Европы, отнюдь не служит делу борьбы с расизмом, а наоборот, способствует появлению разного рода действительно расистских публикации, в том числе, в самих США. А методы проведения этой кампании напоминают времена лысенковщины в СССР.
|
Публикуем статью генетика д.б.н. Е.В. Балановской (вернее, раздел в сборнике «Проблема расы в российской физической антропологии» [М., Институт этнологии и антропологии РАН, 2002]). Сегодня эта статья, к сожалению, не менее актуальна, чем пятнадцать лет назад: недавно Science опубликовал статью с предложением отказаться от понятия «раса» в генетических исследованиях. И это при том, что именно генетические исследования доказывают реальность существования рас.
|
Авторы статьи в Science утверждают, что в современной генетике понятие «раса» - бесполезный инструмент при характеристике генетического разнообразия человечества. Учитывая проблемы, связанные с неправильным употреблением термина, они предлагают вообще от него отказаться. Правда, рассуждения авторов касаются только генетики, они не рассматривают понятие "раса" в рамках антропологии.
|
Генетики исследовали популяцию уйгуров, по одной из версий являющихся генетическими потомками тохаров. Через ареал уйгуров проходил Великий Шелковый путь, соединявший Восточную Азию с Центральной Азией и Европой. Результаты, полученные по STR маркерам Y-хромосомы, подтверждают гипотезу, что в формировании современного генофонда уйгуров сыграли почти равную роль как европейские так и восточноазиатские популяции, но все же с преобладанием вклада генофондов Западной Евразии.
|
Секвенирование 55 древних митохондриальных геномов (возраст – от 35 до 7 тысяч лет), выявило в них варианты, которые не встречены в современном населении Европы. Описав демографические изменения в их связи с изменениями климата, коллектив Йоханеса Краузе (Йена) пришел к выводу, что около 14,5 тысяч лет назад в Европе радикально изменился генофонд охотников-собирателей.
|
Евразийский вклад в генофонд африканских популяций существует, но не столь велик – он обнаруживается не на всем континенте, а в основном в Восточной Африке. Важно, что ошибка признана авторами статьи публично и бесконфликтно - это – признак «здоровья» генетического консорциума.
|
Публикуем статью проф. Л.С.Клейна (вышедшую в журнале "Археологические Вести", 21, 2015) о том, как д.х.н. А.А.Клесов, занявшись темой происхождения славян, связывает ее с вопросом о «норманнской теории», хотя это совсем другая тема - происхождения государственности у восточных славян.
|
Путем секвенирования геномов из семи популяций исследователи подтвердили картину расселения человека по континентам после выхода из Африки. Серия миграций сопровождалась снижением генетического разнообразия. По этой же причине с увеличением расстояния от Африки возрастает мутационный груз в популяциях.
|
Две статьи с данными по секвенированным древним геномам дополнили представления о том, какую роль играли исторические миграции – римского времени и англосаксонская – в формировании современного генофонда Великобритании. Так, уточненный генетический вклад англосаксонских переселенцев составляет около 40% в восточной Англии и 30% - в Уэльсе и Шотландии.
|
Четыре секвенированных генома древних жителей Ирландии (один эпохи неолита, три – бронзового века) указывают, что генофонд Британских островов, как и остальной Европы, сформировался при смешении западно-европейских охотников-собирателей с неолитическими земледельцами, прибывшими с Ближнего Востока, и с более поздней миграцией, берущей начало из степей Евразии.
|
11-13 октября в Йене, Германия в Институте наук об истории человека общества Макса Планка (Max Planck Institute for the Science of Human History) прошла первая междисциплинарная конференция, посвященная недавним генетическим открытиям о миграциях индоевропейцев. Генетики, археологи и лингвисты собрались вместе, чтобы обсудить, как полученные ими последние данные интегрируются в индоевропейскую проблему. Приводим обзор основных идей участников конференции, которые они изложили в своих выступлениях.
|
Публикуем рецензию д.и.н. профессора Ф.Х. Гутнова на брошюру г-на Тахира Моллаева (работника Национального парка «Приэльбрусье», бывшего заочника-филолога КБГУ), «Новый взгляд на историю осетинского народа». Редакция особо отмечает, что пантюркистская тенденция никогда в нашей науке не имела ни авторитета, ни поддержки..
|
Якутские лошади – самые северные на планете и самые морозоустойчивые. Прочитав два древних и девять современных геномов и использовав базу данных по другим геномам, команда российских и зарубежных исследователей нашла ответы на два вопроса. Первый вопрос - от каких древних популяций произошли современные якутские лошади. А второй – как им удалось приспособиться к экстремальным условиям якутского климата за такое короткое время.
|
Почти рождественская история с пропавшим листком, поиском автора и ответами проф. Л.С.Клейна на вопросы антинорманиста.
|
Провожая уходящий год, мы решили подвести итоги и выделить наиболее интересные, на наш взгляд, междисциплинарные исследования в области истории популяций, формирования генетического ландшафта мира и этногенеза, которые были опубликованы в 2015 году. Почти все они нашли свое отражение в материалах нашего сайта. Основные открытия года можно сгруппировать в несколько блоков.
|
Генетики исследовали варианты Y-хромосомы у 657 австралийских аборигенов. Среди них оказалось 56% носителей пришлых евразийских гаплогрупп и только 44% носителей коренных гаплогрупп. Авторы подтвердили гипотезу раннего (около 50 тыс. лет назад) заселения Австралии и длительной изоляции Австралии и Новой Гвинеи. Не найдено доказательств миграций в Австралию из Индии в голоцене. А вот европейская колонизация в конце XVIII века драматически снизила разнообразие коренных австралийских гаплогрупп.
|
Продолжаем публиковать фрагмент из книги О.П.Балановского "Генофонд Европы", посвященный анализу полногеномных маркеров ДНК - самых современных и наиболее информативных для анализа генофонда. В этой части описан метод анализа предковых компонентов и его отображение на геногеографических картах народов Европы
|
Следующий фрагмент книги О.П.Балановского "Генофонд Европы" посвящен полногеномным и широкогеномным маркерам ДНК. Это самые современные и наиболее информативные методы анализа генофонда. В первой части главы показано, как выявляемая с их помощью генетическая карта Европы соотносится с географической картой.
|
Продолжаем публиковать фрагмент из книги О.П.Балановского «Генофонд Европы», посвященный митохондриальной ДНК. В нем разбирается географическая и лингвистическая структурированность генофонда Европы, а также гаплотипическое разнообразие по мтДНК и эколого-генетический мониторинг.
|
Доклад доктора биол. наук Л.А.Животовского об изданной им книге «Неизвестный Лысенко» собрал аншлаг в Институте океанологии РАН. Собственно, не сам доклад, а последующее за ним обсуждение этой попытки реабилитации самой одиозной фигуры советской биологии. Свое мнение высказали и специалисты ненавидимой им генетики, и те, для которых драматические события, связанные с «народным академиком» прошлись по судьбам их семей.
|
В публикуемом фрагменте из книги О.П.Балановского «Генофонд Европы» речь идет об одной из трех систем для оценки геномного разнообразия – митохондриальной ДНК (мтДНК). Дается обзор изменчивости генофонда Европы по мтДНК и рассматриваются генетические взаимоотношения популяций в этом зеркале.
|
В статье обсуждается этимология названия города Суздаль, а также предлагается и обосновывается гипотеза происхождения ойконима Суздаль от реконструируемого гидронима Суздаль (Суздаля).
|
В новой статье команды Сванте Паабо представлены антропологические и генетические данные по двум образцам – двум зубам из Денисовой пещеры. Поскольку генетически подтвердилась их принадлежность к денисовскому человеку, а не к неандертальцам, число проанализированных геномов денисовцев теперь увеличилось до трех.
|
В докладе доктора филолог. наук О.А.Мудрака «Язык и тексты восточно-европейской руники» была представлена расшифровка и перевод рунических надписей памятников, найденных на территории Восточной Европы – от Днепра и Кавказа до Поволжья. Прочтение этих надписей привело к неожиданным заключениям относительно языка бытового и официального письма живших на этой территории народов. Почти все они оказались написаны на осетинском языке и очень немногие - на чечено-ингушском.
|
Масштабный научный проект по изучению генофонда (экзомов) коренного населения народов Урало-Поволжья, в том числе генофонда татар, поддержал экс-президент Минтимер Шаймиев. Проект вызвал шумиху среди татарских националистов и тех, кто приписывает ученым националистически ориентированные цели.
|
Последняя часть главы по древней ДНК из книги О.П.Балановского "Генофонд Европы" посвящена Европе бронзового века. Анализируя палеоДНК, генетики подтверждают представления археологов, что бронзовый век был временем активных миграций и радикальных изменений образа жизни. Все большее количество древних геномов позволяет реконструировать направления миграций и связать генетические потоки с конкретными археологическими культурами.
|
Этот фрагмент из главы о древней ДНК книги О.П.Балановского "Генофонд Европы" рассказывает о том, как с помощью изучения палеоДНК можно реконструировать очень важные процессы неолитизации Европы. В том числе, выяснить, какие древние популяции внесли вклад в формирование генофонда европейцев.
|
В следующем разделе главы о древней ДНК из книги О.П.Балановского "Генофонд Европы" мы узнаем о генетических исследованиях находок времен верхнего палеолита и мезолита на территории Евразии.
|
Очередной фрагмент из книги О.П.Балановского "Генофонд Европы" посвящен анализу древней ДНК. Охарактеризованы проблемы и перспективы направления, сложности лабораторной работы и наиболее успешные исследовательские коллективы. Обзор конкретных исследований начинается со среднего палеолита - с результатов анализа ДНК неандертальцев и денисовцев.
|
Секвенировав три древних генома (верхний палеолит и мезолит) из Грузии и Швейцарии, генетики предполагают, что популяция кавказских охотников-собирателей могла быть четвертым источником европейского генофонда. А ее генетический вклад был передан в Европу, Южную и Центральную Азию через миграции степной ямной культуры.
|
Публикуем отрывок из готовящейся к изданию книги проф. Л.С. Клейна "Хохлач и Садовый". В этом фрагменте разбирается вопрос об этнической принадлежности тех, кто оставил донские курганы. Исследователи высказывают разные предположения о том, кому принадлежали курганы: сарматам, аланам или аорсам. Автор останавливается и на том, кто такие аланы и почему разные народы стремятся приписать себе происхождение от них.
|
В этом разделе из книги О.П.Балановского "Генофонд Европы" описывается структура генофонда Европы в зависимости от двух факторов - географического положения и лингвистики. Европейские популяции объединяются в кластеры как по географическому, так и по лингвистическому принципу. Анализ этой структурированности дается на двух уровнях: межэтническом и внутриэтническом.
|
Публикуем очередной фрагмент из книги О.П.Балановского "Генофонд Европы" (выйдет в декабре 2015 г.). В нем представлен обобщенный анализ генофонда Европы по всем гаплогруппам на трех уровнях: региональном, этническом и субэтническом.
|
Публикуем вторую часть беседы с генетиком, специалистом по древней ДНК Вольфгангом Хааком (Max Planck Institute for the Science of Human History) на конференции в Санкт-Петербурге. Во второй части В.Хаак рассказывает Надежде Маркиной о роли, которая играет исследование древней ДНК в реконструкции истории популяций, и о важности мультидисциплинарного подхода.
|
Публикуем первую часть беседы с генетиком, специалистом по древней ДНК Вольфгангом Хааком (Max Planck Institute for the Science of Human History), которая состоялась в Санкт-Петербурге. В первой части Л.С.Клейн и В. Хаак говорят о том, как по изучению древней ДНК специалисты предположили вклад древнего населения степей в европейский генофонд и с какими культурами они его связывают.
|
В бронзовом веке чума была вполне обычным явлением, хотя в то время чумная бацилла еще не научилась передаваться с блохами и не могла вызывать самую опасную разновидность болезни – бубонную чуму. Время возникновения Yersinia pestis и ее этапы на пути превращения в возбудителя смертельной болезни – все это ученые выяснили, прочитав геномы бактерий из древних останков человека.
|
Публикуем следующий фрагмент из книги О.П.Балановского "Генофонд Европы" . В нем представлены карты всех гаплогрупп Y-хромосомы, по которым есть надежные данные об их распространении в Европе. Этот фрагмент можно рассматривать как первую версию Атласа Y-хромосомы в Европе.
|
Публикуем статью С.В.Кончи, посвященную описанию снега и прочих зимних атрибутов в общеиндоевропейском лексическом фонде. Многие специалисты трактуют «зимнию» лексику как указание на расположение прародины индоевропейцев.
|
Вышел новый номер журнала Stratum plus, посвященный раннеславянской археологии Подунавья «Славяне на Дунае. Обретение Родины» . Его редакторы реализовали грандиозный замысел – собрали в номере почти всех наиболее крупных специалистов в этой области, выступивших с обзорными статьями.
|
Последняя серия карт генетических расстояний (из книги О. Балановского «Генофонд Европы») от народов, ничем друг на друга не похожих – ни языком, ни географией. Но зато эти три генофонда окаймляют пространство народов, рассмотренных в пяти предыдущих сериях, и позволяют увидеть, насколько велики различия генофондов европейской окраины Евразии. Эти три этноса – албанцы, шведы, ногайцы - не только географически «расставлены» по трем «концам земли», но и генетически полярно различны, показывая масштаб разнообразия генофонда Европы.
|
В пятой серии карт (из книги О. Балановского «Генофонд Европы») мы видим степень близости к каждой из популяций Европы южных славян - македонцев, сербов, хорватов, боснийцев и герцеговинцев. Географически их объединяет принадлежность к Балканам, а генетическое своеобразие связывается с сохранением субстратного генофонда тех балканских племен и народов, которые стали говорить на славянских языках.
|
Публикуем четвертую серию карт генетических расстояний на основе гаплогрупп Y-хромосомы из книги О.П. Балановского «Генофонд Европы». Эти карты отражают генетический ландшафт северной окраины Балкан, где проживают разноязыкие народы, говорящие на языках трех лингвистических семей.
|
Эта серия карт очередного фрагмента из книги О.П. Балановского «Генофонд Европы» описывает разнообразие Y-хромосомного генофонда Волжско-Уральского региона. Рассмотрена только полоса соседствующих популяций - Башкортостана, Татарстана, Чувашии и Мордовии. Но несмотря на их относительно небольшой суммарный ареал, генофонды оказались своеобразны и даже загадочны.
|
Следующий фрагмент из книги О.П. Балановского «Генофонд Европы» описывает своеобразие генофондов западных и восточных славян. Карты генетических расстояний обобщают разнообразие гаплогрупп Y-хромосомы и позволяют самим убедиться, насколько каждая точка в ареале Европы генетически близка к средним параметрам каждого из народов западных и восточных славян: их генофонды оказались настолько близки, что им хочется дать имя "генофонд северных славян".
|
Публикуем фрагмент из книги О.П. Балановского "Генофонд Европы" (выйдет в декабре 2015 г.). Карты генетических расстояний позволят своими глазами увидеть, насколько генофонд отдельного народа похож на все остальные генофонды Европы. Представлены карты первой из шести серий - "Народы Северо-Восточной Европы": от карел и вепсов, от эстонцев и коми, от литовцев и латышей, от северных русских и финнов.
|
Экспертное мнение проф. Л.С.Клейна на статью С.А.Григорьева "Еще раз о концепции Т.В.Гамкрелидзе и В.В.Иванова и о критических этюдах в индоевропеистике".
|
Представлены итоги проекта «1000 геномов». Секвенированы геномы и экзомы для 2504 индивидов из 26 популяций пяти регионов. Описано свыше 88 млн генетических вариаций. Создана модель реконструкции демографической истории популяций и найдены новые мишени естественного отбора.
|
Замечания проф. Л.С.Клейна, высказанные с позиций археолога, относительно изложения материала по древним геномам в новой статье команды Райха. С точки зрения эксперта в статье недостаточно внимания уделено принадлежности изучаемых образцов конкретным археологическим культурам.
|
В дополненной статье команды Дэвида Райха про исследование естественного отбора по древней ДНК более чем вдвое увеличилось число проанализированных древних геномов. В результате авторы пришли к новым выводам относительно генетического родства популяций, носителей основных археологических культур от раннего неолита до поздней бронзы.
|
Публикуем раздел книги О.П. Балановского "Генофонд Европы" (выйдет из печати в декабре 2015 г.), посвященный чрезвычайно важному в изучении истории народов вопросу - датировках миграций и других исторических событий. Автор описывает способы, которым решают его популяционные генетики, генетические генеалоги, а также останавливается на подходах "ДНК-генеалогии" А.А. Клесова, разъясняя их ошибочность и лженаучность.
|
В заметке описывается проект Лаборатории востоковедения и сравнительно-исторического языкознания Школы актуальных гуманитарных исследований РАНХиГС, связанный с формализацией генетической классификации языков.
|
Захоронение предполагаемых останков цесаревича Алексея и великой княжны Марии Романовых - детей императора Николая II, отложено на неопределенное время. Поэтому предлагаем вновь открыть страницы непростой истории генетической идентификации костных останков из двух захоронений близ Екатеринбурга – именно эти генетические исследования убедили ученых в их принадлежности членам царской семьи. Это отражено в заключении межведомственной правительственной комиссии, но уголовное дело вновь открыто: предстоит повторная экспертиза. В ее преддверии итоги уже пройденного пути подвел директор Института общей генетики РАН член-корреспондент РАН Н.К. Янковский.
|
В статье дается краткая характеристика текущего состояния и актуальных проблем т. н. "ностратической" гипотезы, разработанной в 1960-е гг. В. М. Иллич-Свитычем и А. Б. Долгопольским и предполагающей дальнее генетическое родство между собой ряда крупных языковых семей Старого Света (как минимум - индоевропейской, уральской, алтайской, картвельской и дравидийской).
|
Впервые генетики секвенировали хорошо сохранившуюся в пещере древнюю ДНК с территории Африки, получив первый эталонный африканский геном. Сравнение этого генома с современными указал на масштаб евразийской обратной миграции в Африку, вклад которой составляет 4-7% в современных африканских геномах на всем континенте.
|
В Америке вышла книга британского философа Стивена Лича «Российские перспективы теоретической археологии. Жизнь и труд Льва С. Клейна». Клейна считают самым известным из современных российских археологов на Западе, его больше других переводили, но на деле знают о нем и его идеях очень мало.
|
На рабочем совещании по проекту "Российские геномы" присутствовали организаторы проекта и лидеры всех основных популяционно-генетических коллективов России. Предлагаем Вашему вниманию доклад О.П. Балановского, представленный на этой конференции. В нем, в частности, говорится, что планируемый в проекте анализ триад (отец, мать, ребенок) сокращает объем полезной геномной информации на одну треть, и поэтому вместо 1000 российских геномов фактически будет изучено 666 геномов.
|
О.П. Балановский отвечает А.А. Клесову на его рецензию статьи о генофонде балтов и славян. Тезисы А.А. Клесова о «подгонке генетических данных под лингвистику» и об отсутствии новизны оказываются взятыми с потолка. Примечательно, что критик выдает за выводы статьи то, что выводами совсем не является, и в то же время не замечает настоящих выводов. Очевидно, поверхностное знакомство со статьей, которую он берется рецензировать, рассчитано на таких же поверхностных читателей.
|
Древняя ДНК с Иберийского полуострова, показала, что генетически баски оказались потомками ранних европейских земледельцев и отчасти - местных охотников-собирателей. Представление об их длительной генетической изоляции подтвердилось.
|
Впервые генетикам удалось изучить древнюю митохондриальную ДНК Балканского полуострова – с территории Румынии. Это навело их на мысль о второй волне неолитической миграции в Центральную Европу через Балканы. Именно она внесла вклад в генофонд современных европейцев.
|
Йоганнес Мюллер – археолог, профессор Кильского университета (Германия), известный специалист по неолиту Европы, мегалитам и радиоугеродным датировкам. Публикуем его статью о проблемах воссоздания общественных идентичностей в археологии и генетике в переводе проф. Л.С.Клейна.
|
Профессор Гётеборгского университета Кристиан Кристансен дал интервью соредактору нашего сайта профессору Л. С. Клейну, В беседе специалистов подвергаются обсуждению некоторые заключения авторов статьи, вызывающие споры у археологов.
|
Эта наиболее полная работа по генофонду славянских и балтских народов подводит итоги многолетних исследований. Генетики и лингвисты проследили пути формирования генофонда всех групп славян и балтов одновременно по трем генетическим системам. Прослежено, какие местные популяции впитывал генофонд славян при их расселении по Европе: именно этот глубинный субстрат сформировал основные различия генофондов разных ветвей славян.
|
(краткий вариант)
Опубликована наиболее полная на сегодняшний день работа по изучению генофонда славян и балтов, в которой использован синтез генетики и лингвистики. При распространении по Европе славяне смешивались с местными популяциями, которые составили глубинный субстрат генофондов, отличающий разные ветви славян друг от друга.
|
Перевод статьи Кристиана Кристиансена, профессора университета Гётеборга в Швеции, ведущего специалиста по археологии бронзового века. В статье рассматриваются модели распространения индоевропейских языков в контексте социальных изменений, подтвержденных новыми археологическими данными.
|
Существуют различные точки зрения на прародину сино-кавказской языковой макросемьи (и включенных в нее дене-кавказских языков). Автор, развивая предложенную им несколько лет назад гипотезу локализации прародины дене-кавказской языковой общности в Восточной Евразии, предпринимает попытку показать, что и данные геногеографии приводят нас к такому же выводу.
|
В постсоветскую эпоху специалисты встретились с явлением, которое получило название «альтернативной истории». Что это за явление, чем оно вызвано, какими идеями оно питается и чему служит? Как специалистам следует на него реагировать? Об этом рассуждает доктор исторических наук В.А.Шнирельман.
|
Две статьи, вышедшие почти одновременно в Nature и Science, посвящены генетической реконструкции заселения Америки методами анализа полных геномов. Их выводы схожи. В статье команды Давида Райха (Nature), помимо основной миграции из Сибири, давшей начало всем коренным популяциям Америки, обнаружен – пока загадочный - «австрало-меланезийский след» у некоторых популяций южноамериканских индейцев. В статье команды Эске Виллерслева (Science) обнаружен тот же след, хотя его источник мог включать, кроме Австрало-Меланезии, еще и Восточную Азию.
|
Исследователи математически доказывают связь между лингвистическим и генетическим разнообразием в популяциях Европы. По их мнению, для изученных народов язык точнее, чем география, указывает на генетическое сходство популяций.
|
Группа исследователей из Калифорнии, применив передовые математические методы, получила для распада праиндоевропейского языка дату 6500–5500 лет назад, что соответствует гипотезе, согласно которой прародина индоевропейцев была в степи. Однако лексический материал, взятый ими для анализа, не выдерживает критики, поэтому достоверность результата в целом оказывается сомнительной.
|
В этой статье автор, профессор Л. С. Клейн, рассматривает ряд книг и статей по этногенезу, явно дилетантских, даже если их авторы и принадлежат к сословию ученых (обычно в науках, далеких от темы исследований). Украинские авторы упирают на украинское происхождение индоевропейцев, российские – на исключительную древность праславян и их тождественность с ариями.
|
Впервые по анализу древней ДНК удалось изучить, по каким генам и в каком направлении в популяциях Европы в последние 8 тысяч лет действовал естественный отбор. Под отбором находились аллели толерантности к лактозе, пигментации кожи и глаз, метаболизма, а также роста и веса.
|
Существует ряд методов обнаружения в геноме современного человека фрагментов ДНК, заимствованных из древних популяций. Среди них есть генетические варианты, имеющие приспособительное значение в изменившихся условиях внешней среды и оказавшиеся под положительным отбором.
|
В 2015 году вышла книга украинского профессора и членкора Украинской академии наук А. Г. Химченко с сенсационными выводами о прародине индоевропейцев. В рецензии на эту книгу профессор Л. С. Клейн оценивает ее как низкопробную халтуру, невысоко ставит и самого автора.
|
В геноме современного человека на территории Европы возрастом 37-42 тыс. лет найдено 6-9% неандертальской ДНК. Она была приобретена всего 4-6 поколений назад. Это означает, что метисация сапиенсов и неандертальцев случалась не только на Ближнем Востоке но и в Европе.
|
Критический анализ концепции происхождения индоевропейцев Т.В.Гамкрелидзе и В.В.Иванова предлагает историк Сергей Конча, научный сотрудник Киевского университета им. Шевченко.
|
Генетики секвенировали 102 древних генома и обнаружили динамичную картину перемещений, смешений и замещений популяций Евразии в бронзовом веке. По мнению авторов это дает ключ к загадке распространения индоевропейских языков.
|
Генетики показали родство «Кенневикского человека» с популяциями американских индейцев, а не с полинезийцами и айнами, как первоначально решили антропологи.
|
Анализ полногеномных данных современной популяции Египта и других африканских популяций привел генетиков к выводу о преобладании северного пути (через Египет) при выходе Homo sapiens из Африки.
|
Исследование генофонда Индии по полногеномной аутосомной панели GenoChip указало на преобладание в нем юго-западноазиатского компонента. Также ученые выяснили, что генетический ландшафт Индии довольно точно совпадает с географическим и лингвистическим делением её населения.
|
Полное секвенирование Y-хросомомы в 17 европейских популяциях показало, что от 2,1 до 4,2 тысячи лет назад почти по всей Европе началась Y-хромосомная экспансия — резкое увеличение эффективного размера популяции по мужской линии.
|
Публикуем аналитический обзор дискуссии "Спор о прародине индоариев" от историка, востоковеда, специалиста по древним и современным коммуникациям В.А.Новоженова. В обзоре разбираются аргументы "за" и "против" автохтонной концепции происхождения индоариев и анализируются многочисленные артефакты, свидетельствующие о возникновении и развитии колесных транспортных средств.
|
Публикуем статью доктора истор. наук Ю.Е.Березкина о том, что изучение распространения фольклорных мотивов может стать источником данных о миграциях популяций.
|
Накопленные данные по частотам микросаттелитных гаплотипов Y-хромосомы позволили исследователям обнаружить 11 крупных родословных кластеров в Азии. Их основателей можно считать отцами-основателями современной азиатской популяции, наряду с Чингисханом (Тимучином) и Гиочангом.
|
Публикуем аналитический обзор доктора истор. наук Л.С.Клейна дискуссии о происхождении индоариев. В данном обзоре Л.С.Клейн представил все обсуждаемые гипотезы, их аргументы и контраргументы, приводимые участниками дискуссии.
|
Дискуссия, которая развернулась в формате комментариев к заметке на сайте «Полное секвенирование отдельной гаплогруппы измеряет мутации и выявляет миграции» http://генофонд.рф/?page_id=2536. Тема происхождения индоариев, которая лишь косвенно относится к предмету исследования генетиков, вызвала бурные дебаты между сторонниками разных гипотез.
|
Перепечатываем беседу профессора Е.В Балановской с главным редактором журнала "Панорама Евразии"(Уфа) А.Т. Бердиным. Чем занимается наука геногеография? И почему ей необходимо решительно отмежеваться от ненаучных джунглей ДНК-генеалогии А. Клесова? Чем чреваты попытки дилетантов писать "народную генетическую историю"? Какие субъективные и объективные факторы позволили допустить квази-науку в здание Президиума РАН на карачаево-балкарской конференции?
|
Скифы – один из немногих бесписьменных народов древности, от которых до нас дошли и самоназвание, и достаточно подробные и в целом заслуживающие доверия сведения иноязычных нарративных источников. Тем не менее происхождение скифов остается предметом споров.
|
Изучив 456 секвенированных Y-хромосом из популяций по всему миру, исследователи уточнили и дополнили Y-хромосомное филогенетическое дерево, определили скорость мутирования на Y-хромосоме и обнаружили резкое снижение эффективного размера популяции по Y-хромосоме в районе 10 тысяч лет назад.
|
Исследователи нашли, что в современных популяциях европейцев и азиатов циркулируют фрагменты ДНК, составляющие около 20% генома неандертальцев. У азиатов их оказалось больше, чем у европейцев. Некоторые неандертальские аллели в геноме Homo sapiens поддерживались положительным отбором.
|
На основе полного секвенирования Y-хромосомной гаплогруппы G1 российские и казахские генетики построили детальное филогенетические дерево, вычислили скорость мутирования и генетически обосновали генгеалогию казахского рода аргынов.
|
Публикуем сокращенный вариант ветви дискуссии о гаплогруппах, языках и этносах к статье «ДНК-демагогия Анатолия Клесова», опубликованной в газете «Троицкий вариант-Наука». Обсуждение актуальных вопросов, затронутых в дискуссии, представляет интерес не только для ее участников, но и для широкого круга специалистов.
|
Представляем фрагменты из презентации доктора физико-математических наук, академика РАН Евгения Борисовича Александрова, председателя Комиссии по борьбе с лженаукой РАН «Лженаука в XXI веке в России и мире».
|
Продолжаем публиковать фрагменты из статьи археолога, этнолога и антрополога, доктора исторических наук Виктора Александровича Шнирельмана «Излечима ли болезнь этноцентризма? Из опыта конструирования образов прошлого — ответ моим критикам».
|
Публикуем фрагменты из статьи археолога, этнолога и антрополога, доктора исторических наук Виктора Александровича Шнирельмана «Излечима ли болезнь этноцентризма? Из опыта конструирования образов прошлого — ответ моим критикам», опубликованной в журнале «Политическая концептология» в 2013 году.
|
Урарту, скифы, аланы... Статья Л.С.Клейна в "Троицком варианте" о том, как народы бывшего Советского союза борются за право считаться потомками тех или иных древних народов.
|
«Битва за аланство» вспыхнула с новой силой. Некий анонимный документ, появившийся в интернете под видом резолюции карачаево-балкарской конференции 2014 года, уже привлек внимание общественности. Специалисты разбирают этот документ с позиций науки.
|
Впервые проведен полноценный тест современных филогенетических методов на лексическом материале лезгинской языковой группы.
|
Представляем интервью о проблемах этногенеза, опубликованное на сайте Полит.ру, с доктором исторических наук, археологом и филологом профессором Львом Самуиловичем Клейном и доктором биологических наук, генетиком и антропологом профессором Еленой Владимировной Балановской.
|
Слайд-доклад О.П.Балановского на междисциплинарной конференции в Звенигороде посвящен изучению древней ДНК, современных генофондов, а также сотрудничеству генетиков и этнографов.
|
Экспедиции в Крым проводились на протяжении четырех лет (2010-2013 годы) дружным международным коллективом – украинских и российских генетиков при активной поддержке и участии Меджлиса крымскотатарского народа и многих представителей крымских татар. Цель этой работы - реконструировать все составные части генофонда крымских татар.
|
Генетики изучили рекордное число образцов древней ДНК европейцев и нашли признаки миграции в центральную Европу из причерноморских степей около 4,5 тысяч лет назад. После появления новых генетических данных споры о происхождении индоевропейцев разгораются с новой силой.
|
Слайд-доклад Е.В.Балановской на междисциплинарной конференции в Звенигороде выявляет разногласия между генетиками и этнологами и предлагает конкретные шаги для их преодоления.
|
Чем занимается каждая из этих областей - популяционная генетика и генетическая генеалогия? На этот вопрос отвечают по-разному. В первом диалоге мы попробуем выяснить, как мы видим наши сферы действия.
|
Чем занимается популяционная генетика и генетическая генеалогия? На тот же самый вопрос, что и в первом диалоге, отвечают два известных представителя этих областей - Олег Балановский и Вадим Веренич.
|
Перепечатываем коллективную статью ученых в газете «Троицкий вариант-наука», обеспокоенных снижением иммунитета научного сообщества, допустившего дилетантское выступление А.Клесова на академическую трибуну.
|
В связи с выходом нового исторического журнала «Исторический формат», (о чем сообщил сайт Переформат .ру) мы обратились к историку О.Л.Губареву с просьбой прорецензировать те статьи этого журнала, которые близки его профилю.
|
|

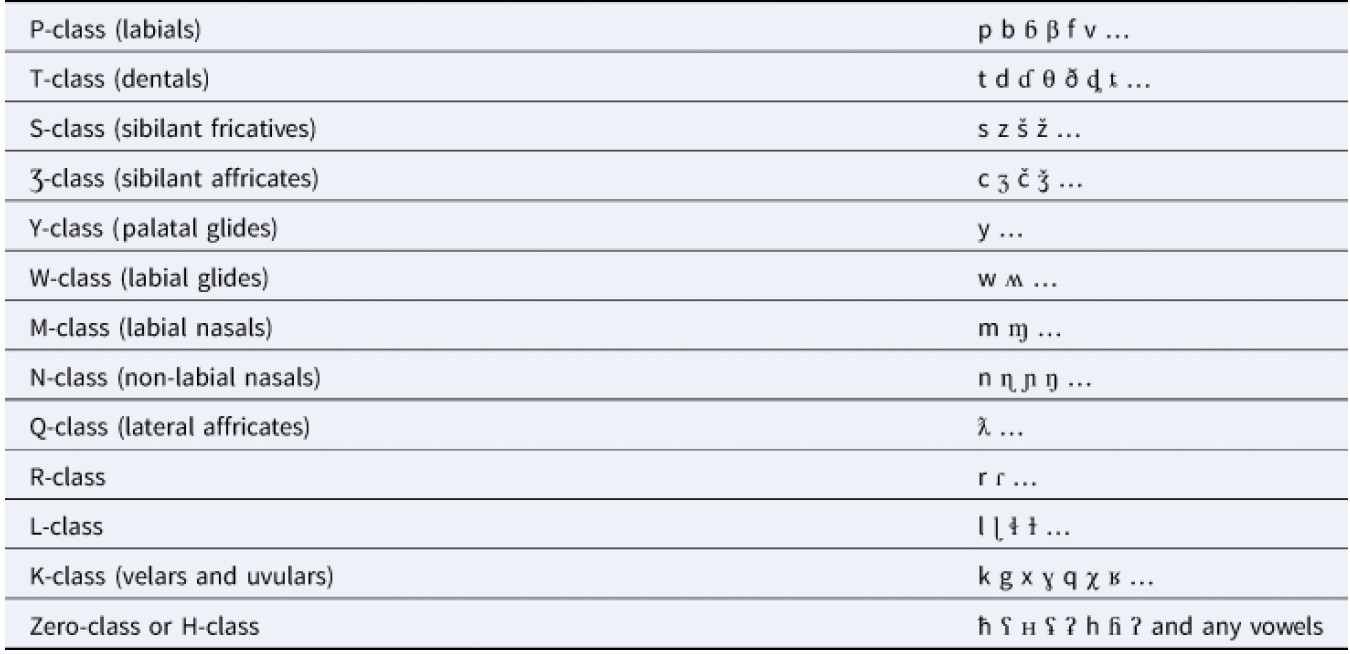
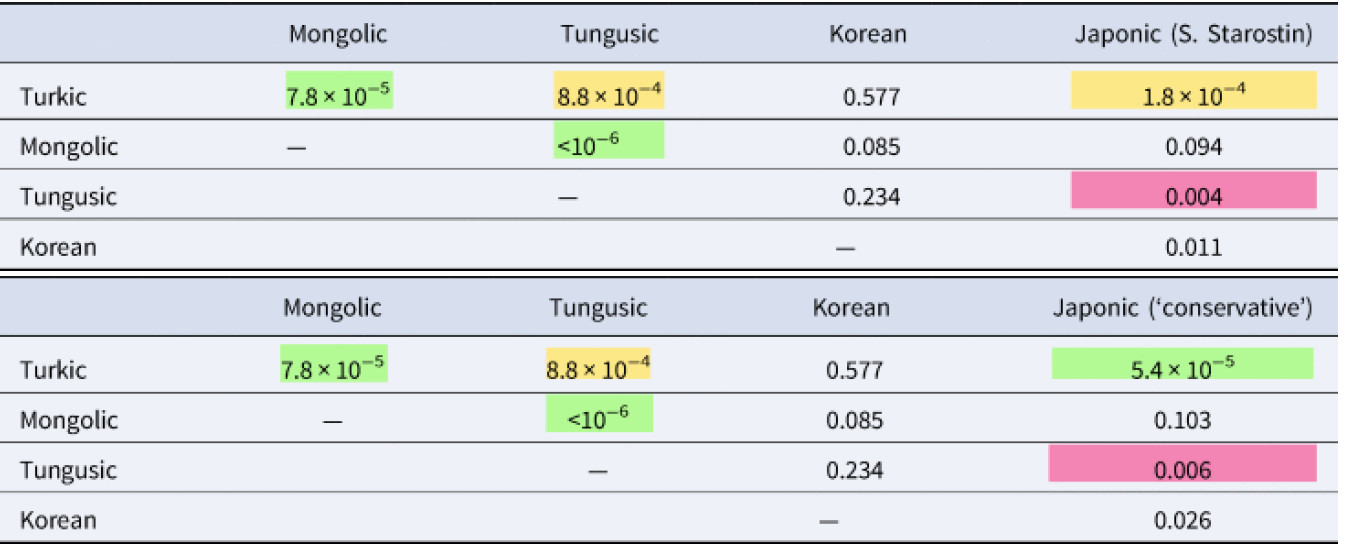
//////что в значении ‘нога’ нужно брать эквивалент ‘foot’, а не ‘leg’; в значении ‘плавать’ брать глагол описывающий действия человека, а не лодки или бревна//////
В этом и заключается главная проблема в применении математических методов к анализу данных лингвистов. Формирование исходных массивов слов (для выполнения их анализа) не формализовано.
Английское FOOT и русское ПЯТА – это две формы одного и того же слова с близкими значениями (Ф <> П). Формы слова восходят к праформе УД в значении в русском языке «всякая конечность».
Русское ПЛАВАТЬ и английское FLOAT – это две формы одного и того же слова, означающие одно и тоже (АВА <> ОА). Причем, в английский язык это слово попало с русской глагольной частицей АТЬ/ИТЬ.
Какой результат дадут математические методы анализа данных, если исходный массив слов сформирую я? Например, мой массив будет содержать всего два слова – FOOT-ПЯТА и ПЛАВАТЬ-FLOAT.
P.S. Я не нашёл сам массив слов, с которым работали авторы статьи. Ссылка из статьи к нему не ведёт. Дайте, пожалуйста, ссылку.
||||||Высокая статистическая значимость совпадений между ядерными алтайскими семьями (тюркской, монгольской и тунгусо-маньчжурской) позволяет трактовать их и как результат контактов, и как следы генетического родства. Мы знаем, что контакты между языками этих семей имели место в древности и продолжаются по сей день. Другое дело статистически значимые совпадения в парах японский-тунгусский и японский-тюркский. Ввиду географической близости можно было бы спекулировать о древних японско-тунгусских контактах (хотя, конечно, намного больше это похоже на древнее родство). Но вот контактный сценарий с заимствованной лексикой между пратюркским и праяпонским требовал бы некоторых сильных допущений по причине громадной географической дистанции между ареалами этих языковых семей.||||||
Одной из основ выделения алтайской языковой семьи являются представления о том, что сообщества, говорящие на тюркском языке, сформировались на территории Восточной Монголии. В том же регионе, где сформировались монгольский и тунгусский языки. То есть, тюркский язык должен иметь примерно такой же уровень не случайного созвучия с японским, как и два других языка. Получается, что авторы статьи оперируют только современной географией языков или отрицают представления о формировании тюркского языка на территории Восточной Монголии.
Мне не понятны сами основы компаративистики.
Например, что имеется в виду под монгольским языком? Не абстрактным, а конкретным с которым работала московская школа компаративистики. В справочнике [http://feb-web.ru/feb/litenc/encyclop/le7/le7-4511.htm] сообщается, что письменный монгольский язык окончательно сформировался в XV в. В нем имеется много заимствований из уйгурского языка. Отмечено: «Живой разговорный монгольский яз. очень сильно отличается от языка письменности, представляя собою в сущности другой язык». Что взять за основу реконструкции прамонгольского языка? Письменный монгольский язык XV в. однозначно искусственный. Сформирован для передачи буддийских духовных текстов. Благодаря заимствованиям из уйгурского языка, выделенные из него редуцированные корни дадут неслучайное созвучие с тюркским языком. Если брать диалекты современного монгольского языка, то они испытали влияние письменного.
Не понятны и частности.
/////// Например, прамонгольское слово *nogoha ‘зеленый’ превращается в NK, также как и пратунгксское *ɲog ‘зеленый’, а прамонгольское *čila ‘камень’ и пратунгусское *ǯolo ‘камень’ становятся ƷL.//////
Сочетание в словах Н_Г может быть следствием трансформации большого юса. В одних словах он закрепился как звук «Г», в других – «Н_Г». Пример: УГР <> ВЕНГР. То есть, прамонгольское слово NOGOHA в других языках может иметь форму GOHA. Эта форма есть в якутском языке – ОТ КҮӨХ: ГОХА = КЫОХ = КК. Но это формально. В бурятском «зелёный» — НОГООН. То есть, ОХ/АК и АН в этих словах суффиксы. А корень слова состоит из одного гласного звука К/Г.
А промонгольское слово ČILA вполне может быть специфической формой слова КАЛА (фарси), которое попало в монгольский через уйгурский язык.
С маньчжурами совсем не понятно. Были чжурчжэни и «малое чжурчжэньское письмо» (МЧП). В соответствии с указом императора Хунтайцзи с 1636 года чжурчжэни стали именоваться маньчжурами. Маньчжурский язык тождествен «малому чжурчжэньскому письму». В справочнике сообщается, что письменность маньчжуров «создана в 1599 на основе монг. алфавита». Наверняка имеется в виду МЧП. То есть, письменные источники по маньчжурскому языку датируются не ранее XVIIв.
Бурыкин: «монгольские и тюркские элементы в лексике языка малого чжурчжэньского письма занимают весьма значительное место и составляют около 20 процентов известного нам лексического состава языка МЧП. … Слова тюркского происхождения в языке МЧП представлены не слишком большим числом примеров».
Исходя из мнения Бурыкина, совершенно непонятны цифры вероятностей фонетических совпадений между тюркским, монгольским и маньчжурским языками (таблица). Вероятность совпадений между монгольским и маньчжурским языками минимальная, а между тюркским и маньчжурским – максимальная. В соответствии с уровнями заимствований должно быть наоборот.
P.S. Плохо, что я не имею возможность посмотреть список слов, с которыми работали авторы статьи.
В открытом доступе со статьей в разделе suppl.mat. находятся и стословник, и файл с пояснениями авторов к каждому слову. За основу для сравнения от каждой семьи берется не набор языков, а реконструированный праязык. Реконструкция же производится на материале всех известных языков семьи, как и в случае с тунгусо-маньчжурской , в которой упомянутый «маньчжурский» — лишь один из…
Из статьи: To view supplementary material for this article, please visit https://doi.org/10.1017/ehs.2021.28
Я нажимаю на ссылку и попадаю опять на эту же статью.
//////Реконструкция же производится на материале всех известных языков семьи, как и в случае с тунгусо-маньчжурской , в которой упомянутый «маньчжурский» — лишь один из…//////
Это правильно. А у каких тунгусо-маньчжурских языков в прошлом имелась своя письменность? Кроме «малого чжурчжэньского письма».
Правильно, другие статьи и не нужны. Сразу под заголовком и списком авторов имеется раздел-распашонка Article. Нажимаете на стрелку V справа, раскроется доп.список, там будут и прилож.мат.
Тунгусы обзавелись письмом недавно.
Спасибо. С приложениями разобрался.
Ещё раз посмотрел Ваш текст. Получается, что тунгусо-маньчжурская семья представлена у вас только тунгусским языком. По современному тунгусскому языку (тому, которые закреплен в недавно созданной письменности) вы реконструировали пратунгусский язык. При этом принимали во внимание и другие языки семьи. Так? А почему вы не выбрали чжурчжэньский язык, закрепленный в «малом чжурчжэньском письме»? Он же гарантированно ближе к некогда единой алтайской мегасемье.
Не уловил что хотели спросить.
Если о словах. «Тунгусы» — я имел в виду не конкретно-этническое, а лингв.определение: носители тунгусских языков тунгусо-маньчжурской семьи. В статье же Tungusic=ТМС «по-русски», т.е. включает и староманьчжурский диалект (чжурчжэней).
Или вопрос был в том, зачем брать другие языки семьи, если можно обойтись чжурчжэньским?